RDP 2026-01: Shock-percentile Restrictions for SVARs 4. Shock-percentile Restrictions
March 2026
This section proposes alternative identifying restrictions that are similar in spirit to shock-magnitude restrictions, but that avoid the difficult problem of eliciting credible numeric bounds on shocks.
4.1 General description
Shock-magnitude restrictions can be viewed as imposing the belief that shocks in selected episodes were ‘large’. Rather than eliciting the definition of ‘large’ based on the distribution of shocks induced by the RWZ algorithm, a natural alternative is to define ‘large’ as being relative to a percentile of the historical distribution of shocks. I refer to such restrictions as ‘shock-percentile restrictions’.
More specifically, let
be the cumulative distribution function (CDF) of the shocks , evaluated at and where For , the quantile function satisfies
A shock-percentile restriction on shock j in period is then
The restriction that shock j in period is smaller than a specified percentile is defined similarly. These restrictions have a natural interpretation as reflecting beliefs about how extreme the shock in a selected episode was, expressed as a relative frequency. To give an example in the context of LMN's model of uncertainty, setting = 1987:M10, j = F and = 0.75 requires the financial uncertainty shock in the Black Monday episode to exceed the 75th percentile of the historical distribution of financial uncertainty shocks; in other words, (positive) shocks more extreme than the shock in this episode occurred in no more than 25 per cent of periods within the sample. In contrast, shock-magnitude restrictions have no such interpretation in the absence of a parametric distributional assumption (e.g. that the shocks are Gaussian).
Shock-percentile restrictions can be used to impose the belief that shocks in selected episodes were large relative to their historical distributions. Importantly, imposing this belief does not require specifying a numeric bound, which as argued above is difficult to credibly elicit. Instead, given a choice of , the bound is a function of the historical distribution of realised shocks. Because the shocks are in general set identified, we do not know the exact realisations of the shocks nor the percentiles of their historical distribution; different values of Q will imply different shock sequences. Some shock sequences may be inconsistent with the shock-percentile restrictions. By ruling out parameter values implying shock sequences where the shock-percentile restrictions are violated, these restrictions may truncate the identified set for Q, sharpening identification.
To illustrate this idea, consider again the SVAR from LMN. Fixing at the OLS estimates, different values of Q will imply different sequences for the financial uncertainty shock The left panel of Figure 3 plots the distribution of at a random value of Q in the unconstrained identified set . In this case, the value of in the Black Monday episode (the dashed line) lies below the 75th percentile of the historical distribution of (the solid line). This value of Q would therefore be ruled out by the shock-percentile restriction (for = 1987:M10). In the right panel, which considers a different value of Q, the realisation of in the Black Monday episode exceeds the 75th percentile of the historical distribution of , so this value of Q would be retained within the identified set given this shock-percentile restriction.
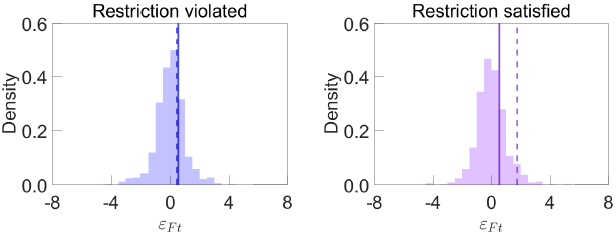
Notes: Each panel represents historical distribution of evaluated at a different (random) value of Q. Solid lines represent 75th percentile of distribution; dashed lines represent value of at = 1987:M10.
Shock-percentile restrictions do not necessarily translate into numeric bounds on shock magnitudes; since the shocks are set identified, in general so is .[14] One case where shock-percentile restrictions can be reformulated as shock-magnitude restrictions is when the shocks are Gaussian. In this case, the population percentiles of the marginal shock distributions are where is the standard normal inverse CDF. Setting to its true value for any .[15] In this case, the unconstrained identified set for would collapse to a point at , and a shock-percentile restriction would resemble a numeric lower bound on the shock; imposing the shock-percentile restriction (9) would be (asymptotically) equivalent to the shock-magnitude restriction . Regardless of whether the underlying shocks are Gaussian, in which case the percentiles of the historical shock distribution are point identified, or non-Gaussian, in which case the historical percentiles may be set identified, shock-percentile restrictions can be used to sharpen identification.[16]
4.2 Numerical example and Monte Carlo exercises
This section illustrates the potential for shock-percentile restrictions to sharpen identification using the simplest possible SVAR – a bivariate SVAR(0).
Let yt = (pt,qt)′, where pt is log price and qt is log quantity. Assume yt is generated according to:
where .[17] Assume a baseline set of sign restrictions on H satisfying
so the first shock can be interpreted as a supply shock that moves prices and quantities in opposite directions, and the second shock can be interpreted as a demand shock that moves prices and quantities in the same direction. The space of 2 × 2 orthonormal matrices can be represented as
where (e.g. Baumeister and Hamilton 2015). The sign restrictions on H generate an identified set for , which is an interval whose end points depend on .[18] The scalar summarises the set-identified component of the model's structural parameters and can be used to illustrate the degree to which the shock-percentile restrictions sharpen identification.
Given a sequence of structural shocks and data , impose a single shock-percentile restriction on the supply shock in period .[19] For the purposes of illustration, the shock-percentile restriction is imposed for different values of The premise of this exercise is that we know the period in which a large supply shock has occurred and impose as an identifying restriction that the shock is large relative to the historical distribution of supply shocks. The exercises here assume that T = 600, which corresponds to 50 years of monthly data. For simplicty, I assume is known and so abstract from sampling uncertainty.
The left panel of Figure 4 plots the identified set for under a combination of the sign restrictions on H and the shock-percentile restrictions. When imposing the sign restrictions only, the identified set for is , where and . Additionally imposing the shock-percentile restriction with narrows the identified set relative to the case where only the sign restrictions are imposed, ruling out lower values of . Imposing the stronger shock-percentile restriction with shrinks the identified set further. This illustration demonstrates that the shock-percentile restrictions may sharpen identification conditional on a single realisation from a data-generating process (DGP).
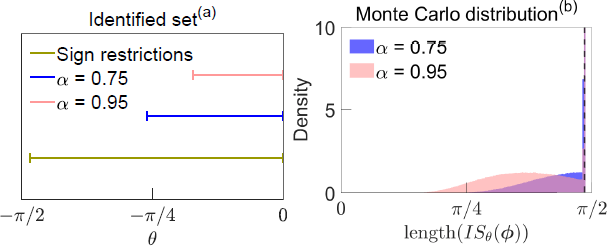
Notes:
(a) Identified set for , under different identifying restrictions, conditional on single realisation from DGP. and add shock-percentile restrictions to sign restrictions on H.
(b) Monte Carlo distribution of length of identified set under combination of baseline and shock-percentile restrictions, where each Monte Carlo replication represents different realisation from DGP. Dashed line is length of identified set under baseline sign restrictions. y-axis truncated for readability.
In the exercise above, the shock-percentile restrictions bind and thus contribute identifying information. However, this is not necessarily the case – whether the restriction binds depends on the realisation of the data. To illustrate this, I repeat this exercise at 10[6] random realisations of the data and compute the length of . The right panel of Figure 4 plots the Monte Carlo distribution of this length.[20] Under the weaker shock-percentile restriction , the identified set is about 7 per cent shorter on average than under the baseline sign restrictions. Even though this shock-percentile restriction tends to sharpen identification on average, in around half of the Monte Carlo replications the restriction contributes no additional identifying information. In contrast, the stronger shock-percentile restriction reduces the length of the identified set by about one-fifth on average and is binding in around 80 per cent of replications.
In this example, the extent to which the shock-percentile restriction sharpens identification depends on how tight identification is under the baseline sign restrictions; when the baseline identified set is already narrow, the restriction is unlikely to bind and the expected reduction in the set's length is small. This example also imposes only a single shock-percentile restriction; imposing multiple restrictions will tend to sharpen identification further. See Appendix B.2 for illustrations of these cases.
4.3 Relationship to other identifying restrictions
Traditional sign restrictions, such as on impulse responses (e.g. Uhlig 2005), directly restrict the SVAR's structural parameters. In contrast, shock-percentile restrictions are restrictions on the structural shocks. They can therefore be viewed as falling within the broader class of ‘narrative restrictions’ proposed in Antolín-Díaz and Rubio-Ramírez (2018) and examined in Giacomini et al (2023).[21] The basic premise of narrative restrictions is that, by forcing the model-implied structural shocks to be consistent with narratives about selected historical episodes, they can constrain the structural parameters and hence sharpen identification.
The shock-percentile restrictions proposed here are novel in that they explicitly involve percentiles of historical shock distributions. However, the shock-percentile restrictions possess similarities to some existing applications of narrative restrictions. When identifying investment-specific technology news shocks, Ben Zeev (2018) restricts the maximal three-year average of the shock to occur during the 1997–1999 period, corresponding to the dot-com boom. When identifying US monetary policy shocks, Giacomini et al (2021) and Read (2022) consider the restriction that the largest absolute realisation of the shock during their sample period occurred in October 1979, corresponding to the Volcker episode. When identifying financial shocks, Abbate et al (2023) impose that the largest contractionary financial shock over their sample period occurred in September quarter 2008, corresponding to the failure of Lehman Brothers. These restrictions have involved restricting a shock in a selected episode to be larger than the realisation of the shock in all other periods. They can therefore be viewed as extreme cases of the shock-percentile restrictions proposed here.[22]
Shock-percentile restrictions differ conceptually to narrative restrictions on the historical decomposition, which were proposed by Antolín-Díaz and Rubio-Ramírez (2018). For example, they restrict the contribution of a shock to the change in a variable over some period to be larger than the contributions of other shocks. These kinds of restrictions assign a larger or smaller role to certain shocks, relative to other shocks, in certain episodes. In contrast, shock-percentile restrictions assume that the realisation of a shock in some period was large relative to other realisations of the same shock, and thus do not directly constrain the role of other shocks in that period.
Shock-percentile restrictions can alternatively be interpreted as restrictions on the contributions of a specific shock to changes in a variable. For example, consider the shock-percentile restriction that the financial uncertainty shock in the Black Monday episode was larger than the 75th percentile of the historical distribution of financial uncertainty shocks. Given the sign normalisation on H, this restriction is equivalent to imposing that the contribution of the financial uncertainty shock to the one-step-ahead forecast error in financial uncertainty in the Black Monday episode exceeds the 75th percentile of the historical distribution of these contributions. This follows from the fact that the rank ordering of the shocks is preserved when multiplying them by a positive constant (here, the impact impulse response of financial uncertainty to the shock, which is normalised to be positive). This interpretation would no longer hold in models where H varies over time.
Footnotes
In the example above, the unconstrained identified set for is [0.43, 0.64]. [14]
If , then , where and H0 is the true value of H. Since the reduced-form parameters are point identified, we can consider setting , and . Since Q is orthonormal, it follows that for any . [15]
For approaches to identifying SVARs that exploit non-Gaussianity of shocks see, for example, Lanne, Meitz and Saikkonen (2017), Braun (2023) and Andrade, Ferroni and Melosi (2024). [16]
I assume Gaussian shocks here for simplicity, but none of the qualitative results substantively depend on this assumption. [17]
See Baumeister and Hamilton (2015) or Read (2024) for a characterisation of this identified set. [18]
The data-generating process underlying this exercise assumes that vec(H) = (1,–0.3, 0.2, 1.2)’, which implies that pt and qt are weakly negatively correlated. [19]
See Appendix B.1 for details about how this Monte Carlo exercise is implemented. [20]
The event constraints proposed in LMN and Ludvigson et al (2017) can also be viewed as narrative restrictions, though they were proposed independently. [21]
The restriction that a shock was the largest realisation of that shock over the sample period is nested within (9) when . Restrictions on the absolute values of shocks can be implemented by replacing the shocks with their absolute values in (7) and (9). [22]