RDP 2026-01: Shock-percentile Restrictions for SVARs Appendix A: Analytical Results and Illustration in Bivariate Model
March 2026
Section 3 argues that the bound-elicitation procedure used in formulating shock-magnitude restrictions generates arbitrary bounds, which casts doubt on the credibility of the restrictions. This appendix provides additional details to support this argument. Section A.1 introduces a simple bivariate model and uses it to show analytically that the unconstrained identified sets for the structural shocks always include zero. This result is then extended to a general n-variable SVAR. Section A.2 uses the bivariate model to illustrate the influence of the algorithm used to randomly draw parameter values in the bound-elicitation procedure.
A.1 Unconstrained identified sets for shocks
This section proceeds by first showing that unconstrained identified sets for structural shocks always include zero using the simplest possible SVAR – a bivariate SVAR with no dynamics – as an example, since the unconstrained identified set can be characterised analytically in this case. I then extend this result to the case of a general n-variable SVAR.
Consider the bivariate SVAR(0), where and . Reparameterise where
and Q is an orthonormal matrix in the space of 2 × 2 orthonormal matrices, can be represented as
where . This formulation of the model, which follows Baumeister and Hamilton (2015), means that the structural parameters can be expressed as functions of and . Restrictions on the structural parameters and/or the structural shocks are then restrictions on .
In the absence of identifying restrictions, the identified set for H is
and the identified set for H–1 is
The sign normalisation generates an unconstrained identified set for [34]
Given a value of the parameters, and , and the realisation of the data in period t, yt, we can use and the expression for H–1 in (A4) to write as
induces a conditional identified set for Evaluating at the end points of yields
Since there exist two values of with opposite signs within the conditional identified set. It immediately follow that contains zero at any value of the reduced-form parameters and at any realisation of the data.[35]
Next, consider an n-variable SVAR. Given an arbitrary value of and ut, the conditional identified set for includes zero if and only if the following set is non-empty:
where the first inequality corresponds to the sign normalisation.[36] Let
If n > 2, we can always find satisfying by computing an orthonormal basis for the null space of W; by the rank-nullity theorem, this null space has dimension . And if some q1 satisfies Wq1 = 02×1 then it clearly also satisfies . The case where n = 2 and corresponds to the bivariate case above, in which it has already been shown that the identified set for the shock includes zero. and ut are arbitrary, so the unconstrained identified set for includes zero at any values of the reduced-form parameters and data.[37]
A.2 Influence of RWZ algorithm on bound elicitation
Section 3 argues that bounds on shock magnitudes elicited using the procedure in LMN could in principle be sensitive to the algorithm used to randomly generate parameter values. This is problematic, because the choice of algorithm is arbitrary in this setting. Using the bivariate model introduced in the previous section, this section illustrates the sensitivity of the bound-elicitation procedure to the choice of algorithm.
In the bivariate model, the distribution for Q induced by the RWZ algorithm corresponds to a uniform distribution for over its identified set; that is, (e.g. Baumeister and Hamilton 2015). Given a realisation of the data yt, the distribution for induces a distribution for via the transformation in (A5). Figure A1 plots these distributions given the same DGP used in Section 4.2 and a single realisation of the data.[38] Given this realisation of the data (and conditioning on the true values of the reduced-form parameters), the conditional identified set for is [–2.4, 2.6], so the data are uninformative about the sign of the shock and its magnitude. The uniform distribution for implies a distribution for that assigns more mass to values towards the upper end of the identified set, and the 75th percentile of this distribution is around 2.4 standard deviations. The bound elicitation procedure in LMN would therefore suggest that it is reasonable to impose the shock-magnitude restriction that
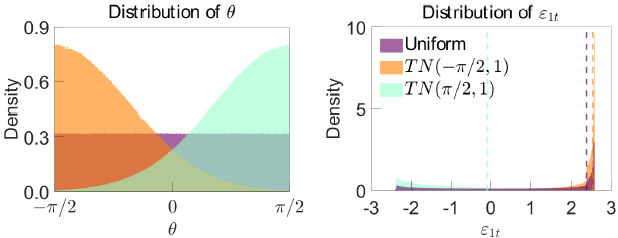
Notes: refers to truncated normal distribution for with mean and unit standard deviation. Dashed lines represent 75th percentiles of shock distribution induced by different distributions for .
What if we used a different algorithm to randomly draw model parameters, corresponding to a different distribution for ? To examine this question, I consider drawing from a truncated normal distribution with mean parameter and standard deviation one, where the lower and upper bounds are and , respectively (i.e. the distribution is truncated to ). I consider , so the two distributions concentrate towards either end of . When the distribution for assigns even more mass towards the upper end of the identified set, pushing up the 75th percentile relative to the case where is uniformly distributed. When the distribution for assigns more mass towards the lower end of the identified set, so the 75th percentile is slightly negative.
Footnotes
An alternative (more tedious) way to show this is to explicitly characterise the conditional identified set. Since is an interval and is a continuous function of is also an interval, so it can be characterised by its end points. The bounds of occur either at the end points of or at a critical point of in the interior of We could therefore characterise the bounds of by comparing the values of evaluated at the critical point and the end points. [35]
The sign normalisations on the remaining columns of Q do not constrain q1; given any we can always iteratively construct the remaining columns of Q such that they are orthogonal to q1 (and each other) and satisfy the sign normalisations. [36]
This result closely parallels Proposition 3.2 in Read (forthcoming), who derives a sufficient condition under which impulse-response identified sets include zero when there are sign and zero restrictions on a single column of Q. [37]
This exercise assumes that Given the value of H in the DGP, this implies that [38]