Research Discussion Paper – RDP 2026-01 Shock-percentile Restrictions for SVARs
1. Introduction
A vast literature uses structural vector autoregressions (SVARs) to identify the effects of structural shocks. The key challenge in doing this is formulating identifying restrictions that are both credible and sufficiently informative to draw economically useful conclusions. In an important contribution, Luvdigson, Ma and Ng (2017, 2021) propose set identifying SVARs using identifying restrictions that include bounds on shocks in selected episodes – what I refer to as ‘shock-magnitude restrictions’. An example is the restriction that the ‘financial uncertainty shock’ in October 1987 – corresponding to the Black Monday stock market crash – was larger than a specified numeric bound (e.g. four standard deviations). In the context of identifying uncertainty shocks, Ludvigson et al (2021) (henceforth, LMN) demonstrate that these restrictions can contribute useful identifying information. A number of papers have adopted shock-magnitude restrictions when identifying uncertainty, and other, shocks.[1]
This paper makes three main contributions. First, I highlight an important feature of the procedure used to specify shock-magnitude restrictions: bounds on shock realisations are typically elicited by inspecting the distribution of shocks induced by simulating values of the SVAR's structural parameters. I argue that the algorithm used to randomly draw parameters is arbitrary in this setting, which casts doubt on the credibility of these restrictions. Second, I propose a novel type of identifying restriction that is similar in spirit to shock-magnitude restrictions, but that avoids specifying numeric bounds on shocks, which are difficult to credibly elicit. The new ‘shock-percentile restrictions’ impose that the realisation of the shock in a selected episode is more extreme than a specified percentile of the shock's historical distribution; an example is the restriction that the financial uncertainty shock in the Black Monday episode exceeds the 75th percentile of the historical distribution of financial uncertainty shocks. Third, using these restrictions I revisit the relationship between uncertainty and real activity, and estimate the macroeconomic effects of US monetary policy. Both applications demonstrate that shock-percentile restrictions can provide useful identifying information.
Imposing shock-magnitude restrictions, as in LMN, requires specifying a numeric bound on a shock in a selected period. Eliciting such a bound on the basis of a priori or narrative information is difficult; while narrative information may suggest that there was a large shock in some period, it is not necessarily obvious how to translate this into a numeric bound. Instead, LMN propose a simulation-based procedure to elicit a bound. This procedure involves randomly drawing values of the SVAR's parameters using an algorithm that I describe below. The distribution of parameter draws induces a distribution for the structural shocks given the observed data. LMN then take a specified percentile of the shock distribution in the selected period and use this to impose a shock-magnitude restriction. For example, in the application considered by LMN, this procedure implies that the 75th percentile of the distribution of the financial uncertainty shock in the Black Monday episode is around 4.2 standard deviations. LMN use this result to motivate a shock-magnitude restriction in which the financial uncertainty shock in that episode is constrained to exceed 4.2 standard deviations.
Shock-magnitude restrictions can be interpreted as representing the belief that a shock was ‘large’, where the definition of ‘large’ is elicited based on the simulation-based procedure described above. In this procedure, the algorithm used to randomly draw parameter values is from Rubio-Ramírez, Waggoner and Zha (2010) (henceforth RWZ). The algorithm draws orthonormal (or ‘rotation’) matrices from a uniform distribution and is employed widely when estimating Bayesian SVARs (e.g. Arias, Rubio-Ramírez and Waggoner 2018; Baumeister and Hamilton 2018). In the Bayesian inferential setting, this uniform distribution has a well-defined interpretation as a prior or posterior distribution.[2] However, in the frequentist setting considered in LMN, the distribution induced by this algorithm has no such interpretation; the algorithm is merely a convenient tool for randomly generating draws of the parameters (Fry and Pagan 2011). Consequently, the distribution of the structural shocks induced by this algorithm is arbitrary, which casts doubt on the credibility of shock-magnitude restrictions.[3]
As an alternative, I propose identifying shocks using novel identifying restrictions that are similar in spirit to shock-magnitude restrictions, but that avoid the difficult problem of specifying numeric bounds on shocks. More specifically, I consider imposing that the shock in a selected episode exceeds a specified percentile of the historical distribution of that shock. These shock-percentile restrictions can be used to impose the belief that a shock was large relative to other realisations of the same shock occurring within the sample. Because these restrictions relate the realisation of a shock to a percentile of its historical distribution, the restrictions have a natural interpretation as reflecting beliefs about how ‘rare’ such a shock is, expressed in probabilistic terms. In contrast, shock-magnitude restrictions have no such probabilistic interpretation in the absence of a parametric distributional assumption about the structural shock (e.g. that it is Gaussian).
Shock-percentile restrictions are identifying restrictions that directly involve the realisations of structural shocks in selected episodes. They therefore fall into the broad class of ‘narrative restrictions’ proposed in Antolín-Díaz and Rubio-Ramírez (2018) and analysed in Giacomini, Kitagawa and Read (2023). Shock-percentile restrictions differ to the specific narrative restrictions proposed in Antolín-Díaz and Rubio-Ramírez (2018), which constrain the signs of structural shocks in selected episodes and/or the relative contributions of shocks to forecast errors (i.e. historical decompositions). While restrictions on the relative magnitudes of structural shocks in different periods have been considered elsewhere, these have typically involved restricting a shock to be larger than the realisation of the shock in all other periods (e.g. Ben Zeev 2018; Giacomini, Kitagawa and Read 2021; Read 2022; Abbate, Eickmeier and Prieto 2023). I demonstrate that much weaker restrictions on the relative size of structural shocks can, in some cases, contribute substantial identifying power. Using a simple model and Monte Carlo exercises, I illustrate the potential for shock-percentile restrictions to sharpen identification. I then apply shock-percentile restrictions in two empirical applications.
First, I revisit the relationship between uncertainty and real activity by replacing the shock-magnitude restrictions in LMN with shock-percentile restrictions. Doing this yields qualitatively similar conclusions about the effects of financial uncertainty shocks on output. In particular, it remains the case that positive financial uncertainty shocks unambiguously lead to a decline in output, and financial uncertainty shocks explain a nontrivial share of output fluctuations beyond short horizons. More generally, however, the shock-percentile restrictions tend to yield ambiguous conclusions about the relationship between uncertainty and real activity. Replacing shock-magnitude restrictions with shock-percentile restrictions in this exercise is therefore an example of the trade-off between ‘credibility’ and ‘certitude’ discussed in Manski (2003, 2011).[4] Imposing an additional shock-percentile restriction related to the 1998 Russian Financial Crisis better disentangles shocks to macroeconomic and financial uncertainty and yields results that are qualitatively consistent with the results from LMN across several dimensions.
Second, I exploit a shock-percentile restriction to sharpen identification of the macroeconomic effects of US monetary policy, building on a model from Antolín-Díaz and Rubio-Ramírez (2018). I start with their narrative restrictions, which constrain the sign of the monetary policy shock and its contribution to changes in the federal funds rate in selected episodes. I then impose a single shock-percentile restriction reflecting the belief that the monetary policy shock in October 1979 – corresponding to the Volcker disinflation – was large relative to the historical distribution of monetary policy shocks. Despite the original narrative restrictions already providing substantial identifying power, this single shock-percentile restriction materially sharpens identification of the output responses to a monetary policy shock; relative to the original set of restrictions, there is much stronger evidence that output declines following a positive shock, especially at short horizons.
Roadmap. Section 2 describes the SVAR, explains the concept of an identified set and defines shock-magnitude restrictions. Section 3 discusses the procedure used to elicit bounds for shock-magnitude restrictions. Section 4 introduces shock-percentile restrictions, illustrates their potential to contribute identifying power in a simple model and relates them to existing identifying restrictions. Section 5 revisits the relationship between uncertainty and real activity, comparing and contrasting results obtained using shock-magnitude and shock-percentile restrictions. Section 6 exploits a shock-percentile restriction to sharpen identification of the effects of US monetary policy. Section 7 concludes. The appendices contain additional details related to the numerical and empirical exercises.
Notation. ei,n is column i of the n×n identity matrix, In. 0n×m is an n×m matrix of zeros. For n×m matrix X, vec(X) is the vectorisation of X, which stacks the elements of X into an nm×1 vector. If X is n×n, vech(X) is the half-vectorisation of X, which stacks the elements lying on or below the diagonal into an n(n+1)/2×1 vector. is the indicator function.
2. Framework
This section describes the SVAR, explains the concept of an identified set and defines shock-magnitude restrictions.
2.1 SVAR
Assume yt = (y1t ,... ,ynt)′ has a reduced-form VAR(p) representation:
where ut are serially uncorrelated reduced-form innovations with and .[5] Let be the lower-triangular Cholesky factor of with non-negative diagonal elements, so . Collect the reduced-form parameters into .
Assume ut is related to the structural shocks by
where and H is invertible. H contains the impact impulse responses of the variables in yt to the structural shocks. The diagonal elements of H are normalised to be non-negative (a ‘sign normalisation’), so a positive realisation of structural shock i does not decrease variable i on impact. Knowledge of H and the reduced-form parameters allows impulse responses and forecast error variance decompositions (FEVDs) to be computed at any horizon.[6]
2.2 Identified sets
In set-identified SVARs, it is common to work with the model's ‘orthogonal reduced-form’ parameterisation (e.g. Arias et al 2018). Let , where is a n×n orthonormal matrix and is the space of all such matrices. In the absence of further identifying restrictions, Q is set identified and, consequently, so is H (e.g. Uhlig 2005; RWZ).
Given a value of define the ‘unconstrained identified set’ for Q as:
Values of Q in are observationally equivalent, in the sense that they correspond to the same second moments of the data, which are summarised by induces an unconstrained identified set for any object of interest that is a function of Q. For example, the unconstrained identified set for H is . Unconstrained identified sets completely characterise the information contained in the data about the objects of interest when imposing only the sign normalisation.
Traditionally, sign or zero restrictions would be imposed on functions of H, shrinking the identified set, with point identification attained if there are sufficiently many zero restrictions. However, as argued in LMN in the context of identifying uncertainty shocks, such restrictions have little theoretical motivation given the ambiguous predictions of different theories of uncertainty.[7] LMN therefore turn to alternative identifying restrictions. These include ‘event constraints’, which are inequality restrictions on structural shocks in selected episodes. I describe these identifying restrictions in detail below. For now, it suffices to note that these identifying restrictions can be written as inequality restrictions on Q. These restrictions can truncate the identified set for Q, sharpening identification of the parameters of interest, but in general leaving them set identified.
Given a generic set of s identifying restrictions, , the identified set for Q is:
In the discussion below, it will become apparent that event constraints depend on additional objects not captured in the definition of , but I suppress this dependence for simplicity.[8] The identified set for Q induces identified sets for other parameters, such as impulse responses and FEVDs.
2.3 Shock-magnitude restrictions
The event constraints proposed in LMN restrict the values of the structural shocks in selected historical episodes. Since , the event constraints represent restrictions on Q that depend on the reduced-form innovations in the constrained periods in addition to the reduced-form parameters .
LMN consider different types of event constraints, which I describe in Section 5. The focus of the following discussion is on the event constraints that involve imposing a bound on a shock in a selected period, which I refer to as shock-magnitude restrictions. A shock-magnitude restriction on shock j in period t takes the form
where is a numeric lower bound (specified by the researcher) and qj is column j of Q.[9] An upper bound would be imposed similarly.
An important input into the shock-magnitude restriction is the bound, k. More-extreme values of k make the restriction more likely to bind and thus truncate the identified set for Q, potentially delivering sharper identification of the SVAR's structural parameters.[10] The next section discusses the procedure proposed in LMN to elicit bounds.
3. Challenges with Eliciting Bounds on Shocks
Imposing a shock-magnitude restriction requires specifying the numeric bound, k, in (5) above. While narrative information may suggest that a shock was large in a specific episode, it is difficult to use this information to formulate a numeric bound on the shock. If we knew that the structural shocks were Gaussian, then restricting a shock to exceed, say, three standard deviations in size could be interpreted as imposing the belief that the period contained a shock with magnitude that is expected to occur with low probability. However, at this point, the SVAR framework considered here makes no parametric distributional assumption about the shocks. It is therefore not obvious whether a shock exceeding three standard deviations is a low-probability event before observing the data and identifying the structural shocks.
Instead, LMN propose a procedure for eliciting bounds on shock magnitudes that uses the observed data and its estimated covariance structure (i.e. the VAR's reduced-form parameters) as inputs. An important additional ingredient in this procedure is an algorithm that is used to simulate values of Q. Section 3.1 describes this algorithm. Section 3.2 then argues that the arbitrary nature of the algorithm in this setting casts doubt on the credibility of the resulting shock-magnitude restrictions. Section 3.3 argues that the procedure would also be problematic if viewed from a Bayesian perspective.
3.1 The RWZ algorithm
A key ingredient in the simulation-based procedure used to elicit the shock-magnitude bounds is an algorithm used to obtain random draws of Q. The algorithm, based on Rubio-Ramírez et al (2010), involves the following steps:
- Draw an n × n matrix of independent standard normal random variables Z.
- Compute the QR decomposition Z = QR, where R is upper-triangular with non-negative diagonal elements.
- Normalise the columns of Q to satisfy
The resulting draws of Q are uniformly distributed over the unconstrained identified set .
3.2 The bound elicitation procedure
In illustrating the procedure proposed by LMN to elicit bounds on shock magnitudes, it is useful to introduce their empirical setting. They use a three-variable SVAR to examine the relationship between real activity and measures of macroeconomic and financial uncertainty in the United States.
Let yt = (Mt, Yt, Ft)′ with corresponding structural shocks is the measure of macroeconomic uncertainty constructed in Jurado, Ludvigson and Ng (2015). This measure averages the square root of conditional forecast error variances of one-step-ahead forecasts across a large panel of macroeconomic data, where the conditional variances are estimated using stochastic volatility models. Underlying this measure is the idea that macroeconomic uncertainty is higher when macroeconomic variables are more difficult to predict. Yt is the log of industrial production, which is a measure of real activity. Ft is a measure of financial uncertainty constructed in the same way as Mt, but based on a large set of financial indicators. The VAR is monthly and contains six lags and a constant. The reduced-form parameters are estimated via ordinary least squares (OLS) over a sample running from July 1960 to April 2015.[11]
LMN use the RWZ algorithm to obtain 1.5 million draws of Q from . Each draw implies a path for the structural shocks, Computing the sequence of shocks at each draw of Q builds up a shock distribution in each period. To motivate their shock-magnitude restrictions, LMN examine these shock distributions. Figure 1 plots the distributions of the ‘financial uncertainty shock’ in September 2008 (the Lehman failure) and October 1987 (the Black Monday episode). In both episodes, the distribution of the shock is right skewed with positive values more likely than negative values.
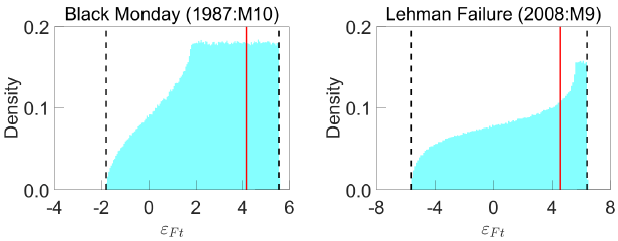
Notes: Distributions of financial uncertainty shocks implied by RWZ algorithm when imposing sign normalisation on impact impulse responses. Solid lines are 75th percentiles; dashed lines are bounds of identified sets.
LMN interpret these results as suggesting that ‘the covariance structure of the data alone provides overwhelming evidence of a large positive financial uncertainty shock in the months of the 1987 crash and the 2008 Lehman collapse’. A similar exercise for the macroeconomic uncertainty shock points to large positive macroeconomic uncertainty shocks in September 2008 (the Lehman episode) and December 1970 (leading up to the collapse of the Bretton Woods system of fixed exchange rates). LMN subsequently formulate shock-magnitude restrictions in these periods, where the bounds (k) are elicited based on these shock distributions. For instance, one exercise in LMN sets lower bounds equal to the 75th percentiles of the shock distributions. To give a specific example, the financial uncertainty shock in the Black Monday episode is restricted to exceed the 75th percentile of the shock distribution in that period, which is around 4.2 standard deviations; that is, the shock-magnitude restriction is for t = 1987:M10.
This procedure has been used by several papers that employ shock-magnitude restrictions (see the references in footnote 1). However, given the sign normalisation, the structural parameters are set identified and any Q in is observationally equivalent. The distribution for Q induced by the RWZ (or any other) algorithm is therefore arbitrary in this setting (e.g. Fry and Pagan 2011; Baumeister and Hamilton 2015, 2024). In turn, the shock distributions induced by the distribution for Q are also arbitrary. Ultimately, this casts doubt on the credibility of shock-magnitude restrictions when the bounds are elicited via this procedure.
To support the claim that the induced shock distribution is arbitrary, I examine unconstrained identified sets for the uncertainty shocks in each month:[12]
These unconstrained identified sets characterise the information about the structural shocks contained in the data, given the sign normalisation. Figure 2 plots the identified sets for the uncertainty shocks in each period. It is apparent that the identified sets for the shocks always span zero, so – given the sign normalisation only – the data and its covariance structure never unambiguously imply whether a positive or negative shock has occurred, much less whether the shock was relatively large or small. At best, we may be able to rule out certain features of the shocks; for example, the identified set for the financial uncertainty shock in the Black Monday episode has a lower bound of around –2 (see Figure 1), so the data are inconsistent with a very large negative financial uncertainty shock in this period. Otherwise, the features of the shock distributions used to elicit the shock-magnitude restrictions depend on the algorithm used to draw Q. If we used a different algorithm, we could obtain a very different distribution.
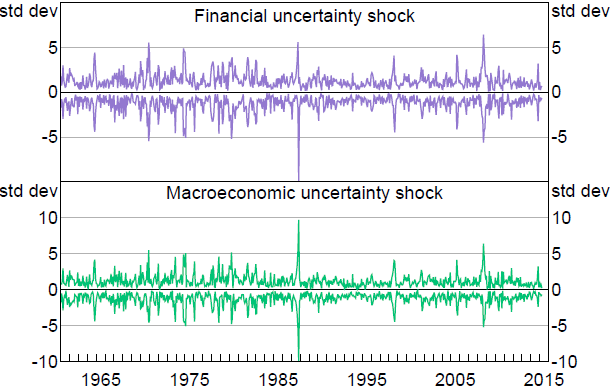
The unconstrained identified sets for the two uncertainty shocks include zero in every period and the data are largely uninformative about the magnitudes of the shocks. A natural question is whether this result is specific to the current application – for example, does it depend on features of the reduced-form parameters? Appendix A.1 shows that, in a general n-variable SVAR, unconstrained identified sets for structural shocks include zero at all possible values of the reduced-form parameters and for any realisation of the data. So the indeterminacy of the shock signs is not peculiar to the current application. Appendix A.2 uses a simple example to illustrate how different algorithms for randomly generating parameters could in principle generate very different shock distributions.
3.3 Can the procedure be motivated from a Bayesian perspective?
In the Bayesian setting, the RWZ algorithm is often used to draw from the posterior distribution under a uniform prior for Q.[13] A Bayesian analogue of the bound-elicitation procedure would be to: 1) specify a prior for and a uniform prior over ; 2) use the posterior for the structural shocks to elicit bounds (e.g. by taking a specified percentile of the posterior distributions of the shocks in selected periods); and 3) use these bounds to impose shock-magnitude restrictions in another SVAR.
There are two main problems with this procedure. First, the obtained bounds may be sensitive to the choice of prior assumed in the first step; since Q is set identified, the conditional prior for Q given is not updated by the likelihood (e.g. Poirier 1998; Moon and Schorfheide 2012). To the extent that the uniform prior does not accurately reflect the researcher's beliefs, this sensitivity is problematic. Second, even if the uniform prior for Q is a good representation of the researcher's subjective beliefs, it is not obvious how one could justify dogmatic identifying restrictions on the basis of the induced posterior over the structural shocks; the posterior merely tells us that some shock values are more or less likely than others, whereas a shock-magnitude restriction dogmatically rules out some shock values. In summary, even with a well-defined subjective (uniform) prior for Q, a Bayesian analogue of the bound-elicitation procedure would generate shock-magnitude restrictions that lack credibility.
4. Shock-percentile Restrictions
This section proposes alternative identifying restrictions that are similar in spirit to shock-magnitude restrictions, but that avoid the difficult problem of eliciting credible numeric bounds on shocks.
4.1 General description
Shock-magnitude restrictions can be viewed as imposing the belief that shocks in selected episodes were ‘large’. Rather than eliciting the definition of ‘large’ based on the distribution of shocks induced by the RWZ algorithm, a natural alternative is to define ‘large’ as being relative to a percentile of the historical distribution of shocks. I refer to such restrictions as ‘shock-percentile restrictions’.
More specifically, let
be the cumulative distribution function (CDF) of the shocks , evaluated at and where For , the quantile function satisfies
A shock-percentile restriction on shock j in period is then
The restriction that shock j in period is smaller than a specified percentile is defined similarly. These restrictions have a natural interpretation as reflecting beliefs about how extreme the shock in a selected episode was, expressed as a relative frequency. To give an example in the context of LMN's model of uncertainty, setting = 1987:M10, j = F and = 0.75 requires the financial uncertainty shock in the Black Monday episode to exceed the 75th percentile of the historical distribution of financial uncertainty shocks; in other words, (positive) shocks more extreme than the shock in this episode occurred in no more than 25 per cent of periods within the sample. In contrast, shock-magnitude restrictions have no such interpretation in the absence of a parametric distributional assumption (e.g. that the shocks are Gaussian).
Shock-percentile restrictions can be used to impose the belief that shocks in selected episodes were large relative to their historical distributions. Importantly, imposing this belief does not require specifying a numeric bound, which as argued above is difficult to credibly elicit. Instead, given a choice of , the bound is a function of the historical distribution of realised shocks. Because the shocks are in general set identified, we do not know the exact realisations of the shocks nor the percentiles of their historical distribution; different values of Q will imply different shock sequences. Some shock sequences may be inconsistent with the shock-percentile restrictions. By ruling out parameter values implying shock sequences where the shock-percentile restrictions are violated, these restrictions may truncate the identified set for Q, sharpening identification.
To illustrate this idea, consider again the SVAR from LMN. Fixing at the OLS estimates, different values of Q will imply different sequences for the financial uncertainty shock The left panel of Figure 3 plots the distribution of at a random value of Q in the unconstrained identified set . In this case, the value of in the Black Monday episode (the dashed line) lies below the 75th percentile of the historical distribution of (the solid line). This value of Q would therefore be ruled out by the shock-percentile restriction (for = 1987:M10). In the right panel, which considers a different value of Q, the realisation of in the Black Monday episode exceeds the 75th percentile of the historical distribution of , so this value of Q would be retained within the identified set given this shock-percentile restriction.
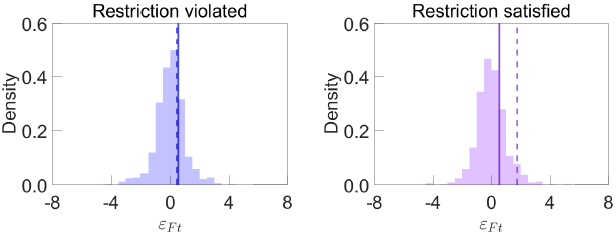
Notes: Each panel represents historical distribution of evaluated at a different (random) value of Q. Solid lines represent 75th percentile of distribution; dashed lines represent value of at = 1987:M10.
Shock-percentile restrictions do not necessarily translate into numeric bounds on shock magnitudes; since the shocks are set identified, in general so is .[14] One case where shock-percentile restrictions can be reformulated as shock-magnitude restrictions is when the shocks are Gaussian. In this case, the population percentiles of the marginal shock distributions are where is the standard normal inverse CDF. Setting to its true value for any .[15] In this case, the unconstrained identified set for would collapse to a point at , and a shock-percentile restriction would resemble a numeric lower bound on the shock; imposing the shock-percentile restriction (9) would be (asymptotically) equivalent to the shock-magnitude restriction . Regardless of whether the underlying shocks are Gaussian, in which case the percentiles of the historical shock distribution are point identified, or non-Gaussian, in which case the historical percentiles may be set identified, shock-percentile restrictions can be used to sharpen identification.[16]
4.2 Numerical example and Monte Carlo exercises
This section illustrates the potential for shock-percentile restrictions to sharpen identification using the simplest possible SVAR – a bivariate SVAR(0).
Let yt = (pt,qt)′, where pt is log price and qt is log quantity. Assume yt is generated according to:
where .[17] Assume a baseline set of sign restrictions on H satisfying
so the first shock can be interpreted as a supply shock that moves prices and quantities in opposite directions, and the second shock can be interpreted as a demand shock that moves prices and quantities in the same direction. The space of 2 × 2 orthonormal matrices can be represented as
where (e.g. Baumeister and Hamilton 2015). The sign restrictions on H generate an identified set for , which is an interval whose end points depend on .[18] The scalar summarises the set-identified component of the model's structural parameters and can be used to illustrate the degree to which the shock-percentile restrictions sharpen identification.
Given a sequence of structural shocks and data , impose a single shock-percentile restriction on the supply shock in period .[19] For the purposes of illustration, the shock-percentile restriction is imposed for different values of The premise of this exercise is that we know the period in which a large supply shock has occurred and impose as an identifying restriction that the shock is large relative to the historical distribution of supply shocks. The exercises here assume that T = 600, which corresponds to 50 years of monthly data. For simplicty, I assume is known and so abstract from sampling uncertainty.
The left panel of Figure 4 plots the identified set for under a combination of the sign restrictions on H and the shock-percentile restrictions. When imposing the sign restrictions only, the identified set for is , where and . Additionally imposing the shock-percentile restriction with narrows the identified set relative to the case where only the sign restrictions are imposed, ruling out lower values of . Imposing the stronger shock-percentile restriction with shrinks the identified set further. This illustration demonstrates that the shock-percentile restrictions may sharpen identification conditional on a single realisation from a data-generating process (DGP).
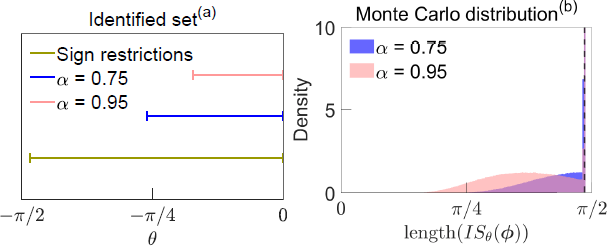
Notes:
(a) Identified set for , under different identifying restrictions, conditional on single realisation from DGP. and add shock-percentile restrictions to sign restrictions on H.
(b) Monte Carlo distribution of length of identified set under combination of baseline and shock-percentile restrictions, where each Monte Carlo replication represents different realisation from DGP. Dashed line is length of identified set under baseline sign restrictions. y-axis truncated for readability.
In the exercise above, the shock-percentile restrictions bind and thus contribute identifying information. However, this is not necessarily the case – whether the restriction binds depends on the realisation of the data. To illustrate this, I repeat this exercise at 10[6] random realisations of the data and compute the length of . The right panel of Figure 4 plots the Monte Carlo distribution of this length.[20] Under the weaker shock-percentile restriction , the identified set is about 7 per cent shorter on average than under the baseline sign restrictions. Even though this shock-percentile restriction tends to sharpen identification on average, in around half of the Monte Carlo replications the restriction contributes no additional identifying information. In contrast, the stronger shock-percentile restriction reduces the length of the identified set by about one-fifth on average and is binding in around 80 per cent of replications.
In this example, the extent to which the shock-percentile restriction sharpens identification depends on how tight identification is under the baseline sign restrictions; when the baseline identified set is already narrow, the restriction is unlikely to bind and the expected reduction in the set's length is small. This example also imposes only a single shock-percentile restriction; imposing multiple restrictions will tend to sharpen identification further. See Appendix B.2 for illustrations of these cases.
4.3 Relationship to other identifying restrictions
Traditional sign restrictions, such as on impulse responses (e.g. Uhlig 2005), directly restrict the SVAR's structural parameters. In contrast, shock-percentile restrictions are restrictions on the structural shocks. They can therefore be viewed as falling within the broader class of ‘narrative restrictions’ proposed in Antolín-Díaz and Rubio-Ramírez (2018) and examined in Giacomini et al (2023).[21] The basic premise of narrative restrictions is that, by forcing the model-implied structural shocks to be consistent with narratives about selected historical episodes, they can constrain the structural parameters and hence sharpen identification.
The shock-percentile restrictions proposed here are novel in that they explicitly involve percentiles of historical shock distributions. However, the shock-percentile restrictions possess similarities to some existing applications of narrative restrictions. When identifying investment-specific technology news shocks, Ben Zeev (2018) restricts the maximal three-year average of the shock to occur during the 1997–1999 period, corresponding to the dot-com boom. When identifying US monetary policy shocks, Giacomini et al (2021) and Read (2022) consider the restriction that the largest absolute realisation of the shock during their sample period occurred in October 1979, corresponding to the Volcker episode. When identifying financial shocks, Abbate et al (2023) impose that the largest contractionary financial shock over their sample period occurred in September quarter 2008, corresponding to the failure of Lehman Brothers. These restrictions have involved restricting a shock in a selected episode to be larger than the realisation of the shock in all other periods. They can therefore be viewed as extreme cases of the shock-percentile restrictions proposed here.[22]
Shock-percentile restrictions differ conceptually to narrative restrictions on the historical decomposition, which were proposed by Antolín-Díaz and Rubio-Ramírez (2018). For example, they restrict the contribution of a shock to the change in a variable over some period to be larger than the contributions of other shocks. These kinds of restrictions assign a larger or smaller role to certain shocks, relative to other shocks, in certain episodes. In contrast, shock-percentile restrictions assume that the realisation of a shock in some period was large relative to other realisations of the same shock, and thus do not directly constrain the role of other shocks in that period.
Shock-percentile restrictions can alternatively be interpreted as restrictions on the contributions of a specific shock to changes in a variable. For example, consider the shock-percentile restriction that the financial uncertainty shock in the Black Monday episode was larger than the 75th percentile of the historical distribution of financial uncertainty shocks. Given the sign normalisation on H, this restriction is equivalent to imposing that the contribution of the financial uncertainty shock to the one-step-ahead forecast error in financial uncertainty in the Black Monday episode exceeds the 75th percentile of the historical distribution of these contributions. This follows from the fact that the rank ordering of the shocks is preserved when multiplying them by a positive constant (here, the impact impulse response of financial uncertainty to the shock, which is normalised to be positive). This interpretation would no longer hold in models where H varies over time.
5. Uncertainty and Business Cycles Revisitede
This section uses the shock-percentile restrictions to revisit the relationship between real activity and uncertainty in the United States, which is the empirical setting examined by LMN. Section 5.1 describes the collection of identifying restrictions imposed by LMN and shows that their shock-magnitude restrictions play a pivotal role in generating their key results. Section 5.2 re-examines these results when replacing the shock-magnitude restrictions with shock-percentile restrictions. Section 5.3 imposes an additional shock-percentile restriction related to the 1998 Russian Financial Crisis. Consistent with LMN, I focus on estimating identified sets and abstract from sampling uncertainty.[23]
5.1 Identifying restrictions in LMN
LMN impose two broad classes of identifying restrictions: 1) ‘external variable constraints’; and 2) ‘event constraints’, which include shock-magnitude restrictions.
5.1.1 External variable constraints
The external variable constraints require the structural shocks to be correlated with variables that are external to the VAR. These constraints do not constrain the external variables to be exogenous with respect to any shocks in the system, unlike much of the literature that makes use of ‘external instruments’ for identification (e.g. Mertens and Ravn 2013; Stock and Watson 2018).
Let St = (S1t, S2t)’ denote a vector of external variables, where S1t is a real stock market return and S2t is the log difference in the real price of gold.[24] The external variable constraints require that
That is, the two uncertainty shocks are required to be negatively correlated with the real stock market return and positively correlated with the change in the real price of gold. Since , it follows that cov The external variable constraints are therefore inequality restrictions on Q. The restrictions depend on the covariances between the external variables St and the reduced-form innovations ut; these covariances constitute additional reduced-form parameters. In what follows, assume additionally contains .
5.1.2 Event constraints
As discussed in Section 2.3, event constraints restrict the values of the structural shocks in specific periods. LMN impose the following event constraints:
- at
- at
- at
- for
- and at
- and at
Constraints (i)–(iii) are shock-magnitude restrictions. Constraint (i) requires the financial uncertainty shock in the Black Monday episode to exceed k1 standard deviations. Constraint (ii) requires the financial uncertainty shock and/or the macroeconomic uncertainty shock in September 2008 (the Lehman Brothers collapse) to exceed k2 and k3 standard deviations in size, respectively. Constraint (iii) requires the macroeconomic uncertainty shock in December 1970 (leading up to the collapse of the Bretton Woods system of fixed exchange rates) to exceed k4 standard deviations. LMN elicit the bounds k = (k1,..., k4)′ using the procedure described in Section 3. In the exercises below, I set these bounds equal to the 75th percentiles of the shock distributions implied by the RWZ algorithm, consistent with one of the specifications in LMN. In practice, this means that k = (4.16,4.57,4.73,4.05)′.
Constraints (iv)–(vi) are additional event constraints motivated by narrative information. Constraint (iv) requires the sum (equivalently, average) of the ‘real activity shocks’ from December 2007 to June 2009 to be positive, corresponding to the Great Recession. Constraints (v) and (vi) require both uncertainty shocks to be non-negative during October 1979 (the Volcker episode) and during the two months corresponding to the US debt ceiling crisis.
5.1.3 Numerical implementation
I approximate identified sets using a large number of draws of Q from the uniform distribution over .[25] Obtaining these draws using the RWZ algorithm and an accept-reject step (as is standard) is computationally burdensome, because is ‘small’ relative to . I therefore employ the ‘soft sign restrictions’ approach developed in Read and Zhu (2025), which can be more computationally efficient when identification is tight. I use around 300,000 draws to approximate the identified sets, motivated by Montiel Olea and Nesbit (2021), who provide results about the number of draws required to approximate identified sets with a specified level of accuracy.[26] See Appendix C.1 for additional details.
5.1.4 Results under LMN restrictions
Figure 5 presents identified sets for the impulse responses under different subsets of the identifying restrictions from LMN.[27] Under the full set of restrictions, a positive financial uncertainty shock unambiguously decreases output at all horizons. A positive macroeconomic uncertainty shock unambiguously increases output at short horizons, which is consistent with ‘growth-options’ theories of uncertainty. Positive shocks to real activity increase financial uncertainty at short horizons but lead to a persistent decrease in macroeconomic uncertainty. These results together suggest that elevated macroeconomic uncertainty during recessions is likely to reflect an endogenous response to adverse shocks associated with business cycle fluctuations. In contrast, heightened financial uncertainty may be an exogenous driver of recessions.
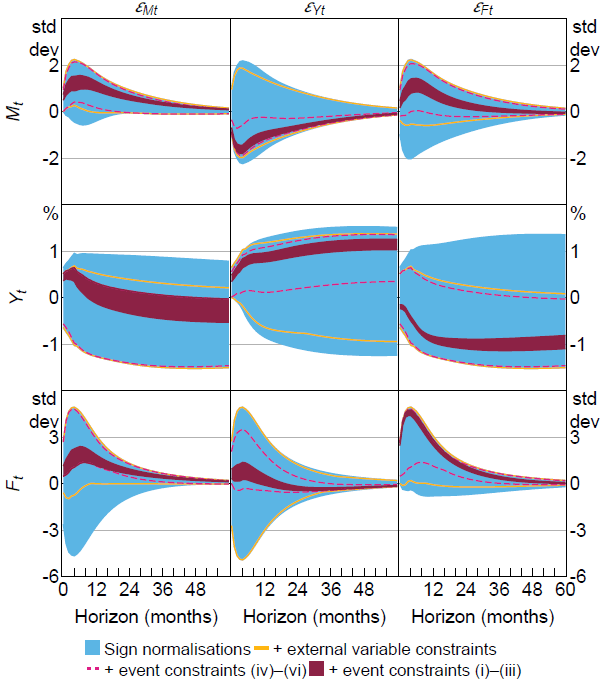
The results under weaker sets of restrictions make it clear that the shock-magnitude restrictions are crucial for obtaining the key results in LMN; in the absence of the shock-magnitude restrictions, identified sets for the output responses to both macroeconomic and financial uncertainty shocks span zero at all horizons. The credibility of the shock-magnitude restrictions is therefore a crucial ingredient in assessing the overall credibility of the results.
5.2 Shock-percentile restrictions
Consider replacing the shock-magnitude restrictions (i)–(iii) with shock-percentile restrictions.[28] More specifically, constraints (i)–(iii) are replaced with:
- * at
- * at
- * at
I initially set , so these shock-percentile restrictions are in a sense analogous to the shock-magnitude restrictions in Section 5.1.2. Constraint (i*) requires the financial uncertainty shock in the Black Monday episode to exceed the 75th percentile of the shock's historical distribution. Constraint (ii*) requires the financial uncertainty shock and/or the macroeconomic uncertainty shock in the Lehman episode to exceed the 75th percentiles of these shocks’ respective historical distributions. Constraint (iii*) requires the macroeconomic uncertainty shock in December 1970 to exceed the 75th percentile of the shock's historical distribution. These restrictions represent the belief that relatively large uncertainty shocks occurred in these periods, without taking a stand on the exact numeric bound that constitutes a ‘large’ shock.
5.2.1 Impulse responses
Figure 6 presents impulse-response identified sets when replacing shock-magnitude restrictions (i)–(iii) with shock-percentile restrictions (i*)–(iii*). The identified sets under the shock-magnitude restrictions are also presented for comparison. Under the shock-percentile restrictions, a positive financial uncertainty shock unambiguously leads to a decline in output at all horizons, which is consistent with the results in LMN. In contrast, identified sets for the output response to a macroeconomic uncertainty shock include zero at most horizons, and the sign of the output response is largely ambiguous. It remains the case that a positive output shock unambiguously decreases macroeconomic uncertainty, consistent with the idea that elevated macroeconomic uncertainty during recessions is likely to reflect an endogenous response to adverse shocks associated with business cycle fluctuations. In contrast, the sign of the response of financial uncertainty to a positive output shock is ambiguous at all horizons; in principle, heightened financial uncertainty during recessions could reflect the endogenous response of financial uncertainty to business cycle fluctuations.
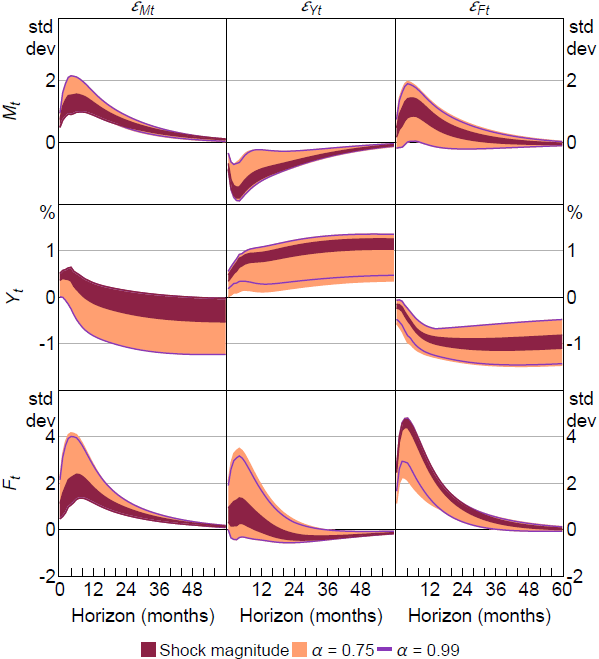
Notes: ‘Shock magnitude’ corresponds to identifying restrictions from LMN, with lower bounds on shock magnitudes based on 75th percentile of shock distribution from bound-elicitation procedure. and replace shock-magnitude restrictions (i)–(iii) with shock-percentile restrictions (i*)–(iii*).
To summarise, replacing the shock-magnitude restrictions with analogous shock-percentile restrictions yields qualitatively similar conclusions about the output effects of financial uncertainty shocks and the response of macroeconomic uncertainty to output shocks. In contrast, there is no longer unambiguous evidence about the output effects of macroeconomic uncertainty shocks or the response of financial uncertainty to output shocks.
Figure 6 also plots the responses obtained under stronger versions of the shock-percentile restrictions, where . These restrictions require the financial and macroeconomic uncertainty shocks in the selected episodes to lie in the upper 1 per cent of the historical distributions of these shocks. Imposing these stronger restrictions narrows the identified sets a little in some cases, but overall there is little substantive difference relative to when .
5.2.2 How important are uncertainty shocks?
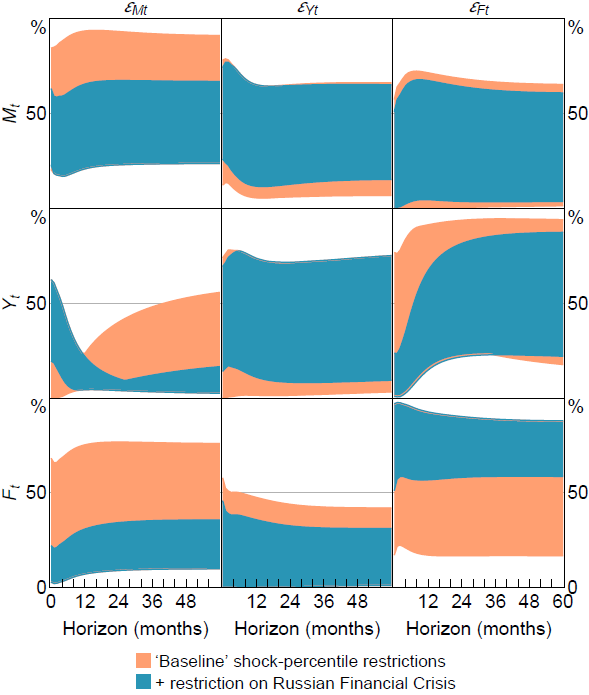
To quantify the importance of different shocks for driving variation in output and uncertainty on average over time, Figure 7 presents identified sets for FEVDs. The identified sets are obtained under the shock-percentile restrictions with and . For comparison, the figure also presents identified sets based on the shock-magnitude restrictions.
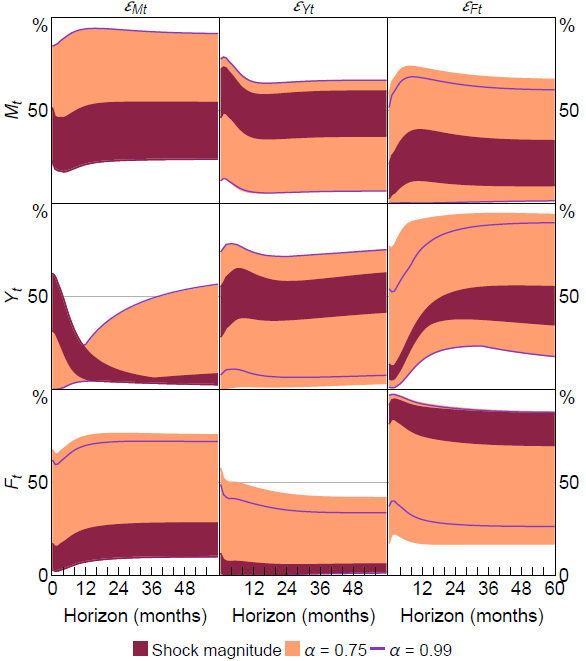
Notes: ‘Shock magnitude’ corresponds to identifying restrictions from LMN, with lower bounds on shock magnitudes based on 75th percentile of shock distribution from bound-elicitation procedure. and replace shock-magnitude restrictions (i)–(iii) with shock-percentile restrictions (i*)–(iii*).
The shock-magnitude restrictions in LMN unambiguously imply that: 1) macroeconomic and financial uncertainty shocks are important drivers of output fluctuations at different horizons, with macroeconomic uncertainty shocks making substantial contributions at shorter horizons and financial uncertainty shocks at longer horizons; 2) the bulk of the variation in financial uncertainty is driven by exogenous shocks to financial uncertainty; and 3) a large share of the variation in macroeconomic uncertainty represents the endogenous response of macroeconomic uncertainty to other shocks.
Under the shock-percentile restrictions, the identified set for the contribution of macroeconomic uncertainty shocks to the forecast error variance of output includes values close to zero at all horizons. This means that there is no longer unambiguous evidence that macroeconomic uncertainty shocks are quantitatively important drivers of output fluctuations at short horizons. The identified sets now also admit the possibility that macroeconomic uncertainty shocks contribute materially to unexpected variation in output at longer horizons.
While the identified sets for the contribution of financial uncertainty shocks to output are substantially wider than obtained under the shock-magnitude restrictions, they still unambiguously imply that financial uncertainty shocks explain a non-trivial share of output fluctuations beyond short horizons; financial uncertainty shocks explain no less than about 20 per cent of unexpected changes in output at the 2-3 year horizon. So these shocks may indeed be an important driver of business cycles, consistent with the VAR analyses in Bloom (2009), Caggiano, Castelnuovo and Groshenny (2014), Leduc and Liu (2016) and Andreasen et al (2024), among others. The identified sets also admit the possibility that financial uncertainty shocks are not the primary driver of output fluctuations at business cycle frequencies, consistent with Brianti (2025).
In terms of what shocks drive measured uncertainty, the identified sets now admit the possibilities that financial uncertainty is largely driven by other (non-financial uncertainty) shocks and that macroeconomic uncertainty is primarily driven by macroeconomic uncertainty shocks. These qualitative conclusions hold both when or when imposing stronger shock-percentile restrictions with .[29]
Overall, relative to the shock-magnitude restrictions, the shock-percentile restrictions deliver less-conclusive evidence about the importance of uncertainty shocks for driving measured uncertainty and real activity.
5.2.3 Understanding the results
While the shock-percentile restrictions in this example generate wider identified sets than the shock-magnitude restrictions, the results are obtained without relying on the arbitrary algorithm used to simulate parameter values. In that sense, replacing shock-magnitude restrictions with shock-percentile restrictions in this application can be viewed as an example of the trade-off between ‘credibility’ and ‘certitude’ discussed in Manski (2003, 2011). But why do the shock-percentile restrictions generate wider identified sets than the shock-magnitude restrictions?
To examine this question, the left panel of Figure 8 visualises the joint unconstrained identified set for the financial uncertainty shock in the Black Monday episode and the 75th percentile of the historical distribution of financial uncertainty shocks . Each point in the shaded region represents a pair corresponding to a value of Q in the unconstrained identified set . Points lying above the dashed line satisfy the shock-percentile restriction . Points lying above the solid horizontal line satisfy the shock-magnitude restriction . It is evident that there are no values of where the shock percentile exceeds the bound on the shock; in this sense, the shock-percentile restriction is strictly weaker than the shock-magnitude restriction. This is also the case for the other periods where these restrictions are imposed. Hence, the shock-percentile restrictions, when combined with the other identifying restrictions, generate wider identified sets than the shock-magnitude restrictions.
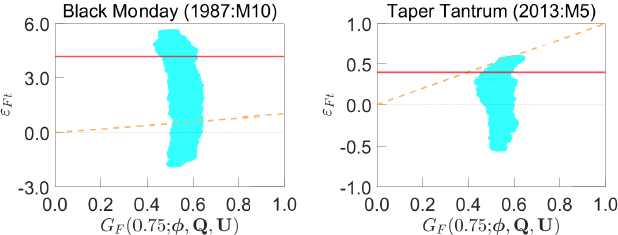
Notes: Shaded region represents joint unconstrained identified set for financial uncertainty shock in selected episode and historical shock percentiles . Points lying above the dashed line satisfy the shock-percentile restriction and points lying above the solid line satisfy the shock-magnitude restriction.
A natural question is: will it always be the case that a shock-percentile restriction is weaker than an analogous shock-magnitude restriction when the bound is elicited using the procedure in LMN? The answer is no. To illustrate, consider the financial uncertainty shock in the Taper Tantrum episode ; this was a period of volatility in financial markets, which was triggered by suggestions that the Federal Reserve might reduce the pace of bond purchases under its quantitative easing program. The right panel of Figure 8 shows that all values of that satisfy a shock-percentile restriction based on this episode also satisfy the analogous shock-magnitude restriction. The shock-percentile restriction would therefore be unambiguously stronger than the shock-magnitude restriction.
5.3 Additional restrictions
The shock-percentile restrictions considered above yield conclusions about the effects of uncertainty shocks that are qualitatively consistent, along some dimensions, with the results obtained under the shock-magnitude restrictions. However, as discussed, the identified sets tend to be substantially wider, so while the results are arguably more credible, they are in a sense less economically informative. It is therefore valuable to impose additional credible identifying restrictions to sharpen identification.
To that end, I impose an additional shock-percentile restriction related to the 1998 Russian Financial Crisis. More specifically, I restrict the financial uncertainty shock in August 1998 to exceed the 75th percentile of the historical distribution of uncertainty shocks. This is the month in which Russia defaulted on ruble-denominated government debt and devalued the ruble, triggering a spike in uncertainty in financial markets; for example, the CBOE Volatility Index (VIX) roughly doubled over August. This episode led to the near collapse of the hedge fund Long-Term Capital Management, which was subsequently (in September 1998) bailed out by a consortium of private banks in a deal facilitated by the Federal Reserve (e.g. Lowenstein 2000).
Augmenting the restrictions from Section 5.2 with the additional shock-percentile restriction substantially sharpens identification of the impulse responses to the uncertainty shocks, better disentangling shocks to macroeconomic and financial uncertainty (Figure 9). For example, output unambiguously increases at short horizons following a positive macroeconomic uncertainty shock, and macroeconomic uncertainty unambiguously increases following a positive financial uncertainty shock; these results are broadly consistent with the results from LMN.
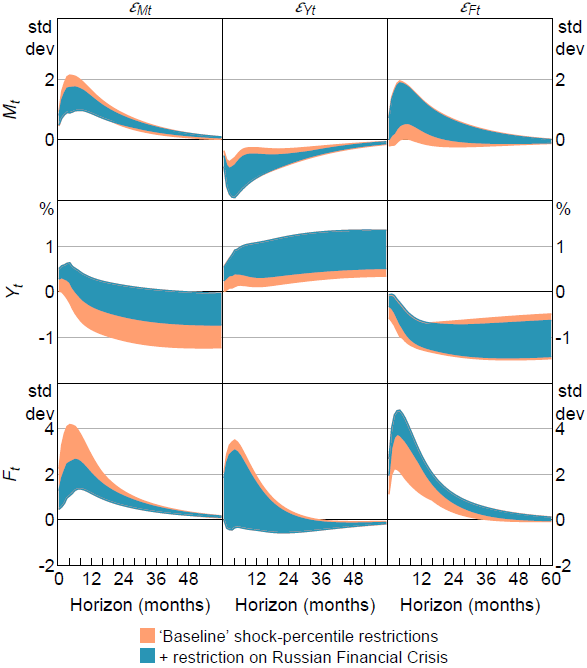
The additional shock-percentile restriction also tightens identified sets for the FEVDs, delivering less-ambiguous evidence about the importance of the different shocks for driving variation in output and measured uncertainty (Figure 10). More specifically: financial uncertainty shocks unambiguously explain at least half of the forecast error variance of financial uncertainty at all horizons, so most of the variation in financial uncertainty is driven by exogenous shocks to financial uncertainty; a substantial share of the variation in macroeconomic uncertainty is now unambiguously ascribed to other shocks; and macroeconomic uncertainty shocks unambiguously make a material contribution to output fluctuations at short horizons and a limited contribution at longer horizons, and vice versa for financial uncertainty shocks. These results are broadly consistent with those obtained under LMN's shock-magnitude restrictions. Importantly, however, they are obtained without specifying an arbitrary numeric lower bound on shock magnitudes, and so may be viewed as more credible.
6. Estimating the Effects of US Monetary Policy
This section applies a shock-percentile restriction to help identify the effects of US monetary policy, building on Antolín-Díaz and Rubio-Ramírez (2018) (henceforth, AR18). They identify US monetary policy shocks using a combination of sign restrictions on impulse responses (as in Uhlig (2005)) and narrative restrictions. I consider augmenting their narrative restrictions with a shock-percentile restriction, reflecting the belief that the monetary policy shock in October 1979 (the Volcker episode) was large relative to the historical distribution of monetary policy shocks, consistent with the view that the shock in this episode represented a ‘major anti-inflationary shock to monetary policy’ (Romer and Romer 1989, p 142).
6.1 Reduced-form VAR
The reduced-form VAR is from Uhlig (2005). The endogenous variables are real GDP, the GDP deflator, a commodity price index, total reserves, non-borrowed reserves (all in natural logarithms) and the federal funds rate. The data are monthly, with the sample beginning in January 1965 and ending in November 2007. The VAR includes 12 lags. As discussed further below, I estimate the model using a prior-robust Bayesian method under the assumption that the structural shocks are normally distributed. The prior for the reduced-form parameters is the uninformative Jeffreys’ prior, so the posterior is normal-inverse-Wishart.
6.2 Identifying restrictions
As identifying restrictions, AR18 impose a mix of sign restrictions on impulse responses and narrative restrictions. The sign restrictions follow Uhlig (2005): the response of the federal funds rate to a positive monetary policy shock is non-negative for h = 0,1,...,5; and the responses of the GDP deflator, the commodity price index and non-borrowed reserves are non-positive for h = 0,1,..., 5. As narrative restrictions, they impose that the monetary policy shock in October 1979 was positive and was the ‘overwhelming contributor’ to the observed unexpected change in the federal funds rate. The narrative restrictions represent the belief that the monetary policy shock in this episode was large relative to other shocks in the same period in terms of the shocks’ contributions to the change in the federal funds rate. In an additional exercise involving a richer set of narrative restrictions, the restrictions are that the monetary policy shock was: positive in April 1974, October 1979, December 1988 and February 1994; negative in December 1990, October 1998, April 2001 and November 2002; and the ‘most important contributor’ to the observed unexpected change in the federal funds rate in these months.[30]
To examine the identifying power of a shock-percentile restriction in this setting, I additionally impose the shock-percentile restriction that the monetary policy shock in the Volcker episode exceeded the 90th percentile of the historical distribution of monetary policy shocks.[31] Unlike the restrictions on the historical decomposition, this shock-percentile restriction represents the belief that the monetary policy shock in the Volcker episode was large relative to monetary policy shocks occurring in other periods. Imposing both restrictions in this episode therefore represents the belief that the monetary policy shock was ‘large’ along two dimensions: 1) its contribution to the change in the federal funds rate in this period relative to the contributions of other shocks; and 2) relative to other periods.
6.3 Results
I estimate the impulse responses to a 100 basis point monetary policy shock both under the identifying restrictions from AR18 and when additionally imposing the shock-percentile restriction. To do this, I use the prior-robust Bayesian approach to inference developed in Giacomini and Kitagawa (2021a) and extended to the case of narrative restrictions in Giacomini et al (2023). This approach to inference provides a tractable way to account for sampling uncertainty when estimating identified sets; the ‘set of posterior medians’ under this approach can be interpreted as an estimator of the identified set and the ‘robust credible interval’ can be interpreted as an asymptotically valid frequentist confidence interval for the identified set.[32]
Figure 11 plots the impulse responses of the federal funds rate and output to a monetary policy shock that increases the federal funds rate by 100 basis points on impact. Under the original Volcker restrictions (left panels), the set of posterior medians for the output response contains zero at almost all horizons considered.[33] In contrast, when augmenting these restrictions with the shock-percentile restriction, the set of posterior medians excludes zero at most horizons within the first three years. One way to quantify the evidence about the output response is to use the ‘posterior lower probability’; this is the smallest posterior probability assigned to a particular hypothesis under the ‘class of posteriors’ underlying the robust Bayesian approach to inference. The posterior lower probability that the output response is negative at the six-month horizon is less than 1 per cent under the original restrictions, whereas it is around 65 per cent when additionally imposing the shock-percentile restriction. Hence, there is much stronger evidence of a decline in output at this (relatively short) horizon following a monetary policy shock. Overall, augmenting the baseline narrative restrictions with the shock-percentile restriction yields stronger evidence that output falls following a positive monetary policy shock, particularly at shorter horizons.
Under the extended set of restrictions from AR18 (right panels, Figure 11), the set of posterior medians includes zero at all horizons within the first year or so. This is no longer the case when additionally imposing the shock-percentile restriction; the estimator of the identified set unambiguously points to an output decline at almost all horizons beyond the first six months. The posterior lower probability that the output response is negative at the six-month horizon is about 65 per cent when imposing the shock-percentile restriction, compared with only 14 per cent under the original set of restrictions. So, again, there is much stronger evidence of a decline in output at short horizons when additionally imposing the shock-percentile restriction.
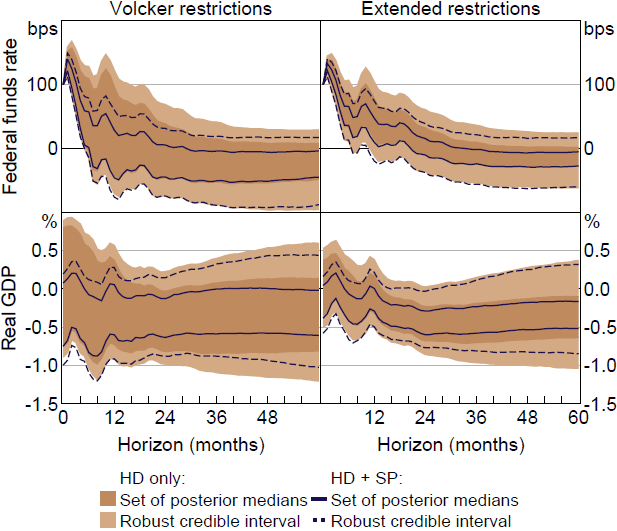
Notes: Impulse responses are to a 100 basis point monetary policy shock. ‘HD only’ represents results under identifying restrictions from Antolín-Díaz and Rubio-Ramírez (2018); ‘HD + SP’ additionally imposes shock-percentile restriction. Robust credible intervals are at the 68 per cent level.
To summarise, imposing a single shock-percentile restriction related to the Volcker episode substantially sharpens identification of the output effects of US monetary policy, yielding stronger evidence that output declines following a positive monetary policy shock, particularly at short horizons. This is the case even when imposing this restriction on top of an already rich set of narrative restrictions.
7. Conclusion
Identifying SVARs by imposing numeric bounds on shocks is inherently difficult. Instead, shock-percentile restrictions are based on beliefs about the size of shocks in selected episodes relative to the shock's historical distribution. These restrictions may therefore provide a more credible approach to sharpening identification in settings where narrative information suggests that shocks in selected episodes were relatively large, but the precise magnitudes of these shocks are uncertain.
Appendix A: Analytical Results and Illustration in Bivariate Model
Section 3 argues that the bound-elicitation procedure used in formulating shock-magnitude restrictions generates arbitrary bounds, which casts doubt on the credibility of the restrictions. This appendix provides additional details to support this argument. Section A.1 introduces a simple bivariate model and uses it to show analytically that the unconstrained identified sets for the structural shocks always include zero. This result is then extended to a general n-variable SVAR. Section A.2 uses the bivariate model to illustrate the influence of the algorithm used to randomly draw parameter values in the bound-elicitation procedure.
A.1 Unconstrained identified sets for shocks
This section proceeds by first showing that unconstrained identified sets for structural shocks always include zero using the simplest possible SVAR – a bivariate SVAR with no dynamics – as an example, since the unconstrained identified set can be characterised analytically in this case. I then extend this result to the case of a general n-variable SVAR.
Consider the bivariate SVAR(0), where and . Reparameterise where
and Q is an orthonormal matrix in the space of 2 × 2 orthonormal matrices, can be represented as
where . This formulation of the model, which follows Baumeister and Hamilton (2015), means that the structural parameters can be expressed as functions of and . Restrictions on the structural parameters and/or the structural shocks are then restrictions on .
In the absence of identifying restrictions, the identified set for H is
and the identified set for H–1 is
The sign normalisation generates an unconstrained identified set for [34]
Given a value of the parameters, and , and the realisation of the data in period t, yt, we can use and the expression for H–1 in (A4) to write as
induces a conditional identified set for Evaluating at the end points of yields
Since there exist two values of with opposite signs within the conditional identified set. It immediately follow that contains zero at any value of the reduced-form parameters and at any realisation of the data.[35]
Next, consider an n-variable SVAR. Given an arbitrary value of and ut, the conditional identified set for includes zero if and only if the following set is non-empty:
where the first inequality corresponds to the sign normalisation.[36] Let
If n > 2, we can always find satisfying by computing an orthonormal basis for the null space of W; by the rank-nullity theorem, this null space has dimension . And if some q1 satisfies Wq1 = 02×1 then it clearly also satisfies . The case where n = 2 and corresponds to the bivariate case above, in which it has already been shown that the identified set for the shock includes zero. and ut are arbitrary, so the unconstrained identified set for includes zero at any values of the reduced-form parameters and data.[37]
A.2 Influence of RWZ algorithm on bound elicitation
Section 3 argues that bounds on shock magnitudes elicited using the procedure in LMN could in principle be sensitive to the algorithm used to randomly generate parameter values. This is problematic, because the choice of algorithm is arbitrary in this setting. Using the bivariate model introduced in the previous section, this section illustrates the sensitivity of the bound-elicitation procedure to the choice of algorithm.
In the bivariate model, the distribution for Q induced by the RWZ algorithm corresponds to a uniform distribution for over its identified set; that is, (e.g. Baumeister and Hamilton 2015). Given a realisation of the data yt, the distribution for induces a distribution for via the transformation in (A5). Figure A1 plots these distributions given the same DGP used in Section 4.2 and a single realisation of the data.[38] Given this realisation of the data (and conditioning on the true values of the reduced-form parameters), the conditional identified set for is [–2.4, 2.6], so the data are uninformative about the sign of the shock and its magnitude. The uniform distribution for implies a distribution for that assigns more mass to values towards the upper end of the identified set, and the 75th percentile of this distribution is around 2.4 standard deviations. The bound elicitation procedure in LMN would therefore suggest that it is reasonable to impose the shock-magnitude restriction that
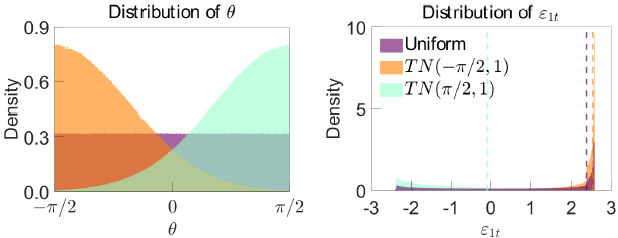
Notes: refers to truncated normal distribution for with mean and unit standard deviation. Dashed lines represent 75th percentiles of shock distribution induced by different distributions for .
What if we used a different algorithm to randomly draw model parameters, corresponding to a different distribution for ? To examine this question, I consider drawing from a truncated normal distribution with mean parameter and standard deviation one, where the lower and upper bounds are and , respectively (i.e. the distribution is truncated to ). I consider , so the two distributions concentrate towards either end of . When the distribution for assigns even more mass towards the upper end of the identified set, pushing up the 75th percentile relative to the case where is uniformly distributed. When the distribution for assigns more mass towards the lower end of the identified set, so the 75th percentile is slightly negative.
Appendix B: Monte Carlo Exercises
This appendix details how the Monte Carlo exercises in Section 4.2 are implemented and describes the additional exercises that are referred to in the main text.
B.1 Implementation details
In each Monte Carlo replication, the identified set for under the baseline sign restrictions is computed analytically.[39] Under the shock-percentile restriction, the identified set is approximated using draws of Q from the uniform distribution over , obtained via the RWZ algorithm. At each draw of Q, I compute the implied value of , then approximate the identified set by the minimum and maximum values of over the draws.[40] Montiel Olea and Nesbit (2021) provide results about the number of draws required to guarantee a given degree of approximation error. Their Theorem 3 provides an upper bound on the number of draws L from within the identified set required to guarantee that a misclassification error less than occurs with probability at least . The upper bound is where d is the dimension of the parameter region being approximated. Setting d = 1 (since is scalar) and yields an upper bound for L of around 1,060. I therefore approximate using 1,060 draws of Q in each Monte Carlo replication.
Because numerical approximation introduces error, the identified set obtained under the shock-percentile restriction can appear strictly smaller than under the baseline sign restrictions even when the shock-percentile restriction is not actually binding. When computing the share of Monte Carlo replications in which the shock-percentile restriction contributes no additional identifying information, I account for this approximation error by reporting the share of replications where the two identified sets differ in length by no more than 1 per cent.
B.2 Additional exercises
The Monte Carlo exercise in Section 4.2 assumes a DGP where vec(H) = (1, −0.3, 0.2, 1.2)′, which implies that pt and qt are weakly negatively correlated. Under this DGP, the shock-percentile restrictions often (sometimes substantially) sharpen identification. If the correlation were stronger, the identified set would be shorter under the baseline sign restrictions and the shock-percentile restrictions would tend to sharpen identification by less.
To illustrate this, I repeat the Monte Carlo exercise with an alternative DGP that yields tighter identification under the baseline. More specifically, the DGP now assumes that vec(H) = (6, −1.8, 0.2, 1.2)′. Relative to the original DGP, these parameter values imply that the supply shock plays a much more important role in driving variation in pt and qt, inducing a stronger negative correlation between the two variables. Consequently, the identified set under the baseline sign restrictions is about 60 per cent shorter than the identified set under the original DGP.[41]
The left panel of Figure B1 plots the Monte Carlo distribution of the length of the identified set under this alternative DGP. Under the weaker shock-percentile restriction , the identified set is only about 0.1 per cent shorter, on average, than under the baseline sign restrictions, and the shock-percentile restriction is binding in only about 0.1 per cent of Monte Carlo replications. Even the stronger shock-percentile restriction only reduces the length of the identified set by about 1 per cent on average and does not sharpen identification at all in around 94 per cent of replications. Overall, the shock-percentile restrictions tend to be less informative than under the original DGP; they bind less frequently and, conditional on binding, tend to sharpen identification by less.
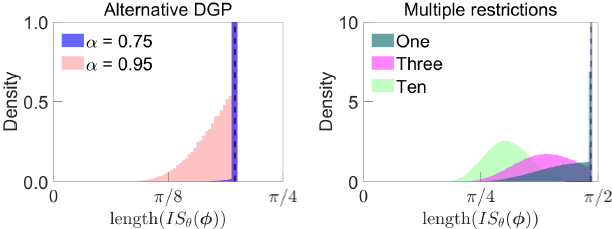
Notes: Monte Carlo distribution of length of identified set under combination of baseline and shock-percentile restrictions, where each Monte Carlo replication represents different realisation from DGP. Left panel assumes alternative DGP with sharper identification under baseline sign restrictions; right panel assumes original DGP and imposes multiple shock-percentile restrictions with Dashed line represents length of identified set under sign restrictions only. y-axes truncated for readability.
The Monte Carlo exercises in Section 4.2 and above impose only a single shock-percentile restriction. Imposing multiple restrictions – as in the empirical application in Section 5 – should tend to sharpen identification further. To illustrate this, I return to the original DGP considered in Section 4.2 and consider imposing multiple ‘weak’ shock-percentile restrictions with . I consider imposing one, three or ten shock-percentile restrictions. In each exercise, the restrictions are imposed in the periods corresponding to the largest positive realisations of ; that is, the shock-percentile restrictions take the form
where is the rth largest order statistic of the shock sequence In the cases considered,
The right panel of Figure B1 plots the Monte Carlo distribution of the length of the identified set for each set of restrictions. It is apparent that adding additional shock-percentile restrictions can substantially sharpen identification; the Monte Carlo distribution of the length of the identified set shifts to the left as more shock-percentile restrictions are added. With three shock-percentile restrictions, the length of the identified set is 18 per cent shorter, on average, than under the baseline sign restrictions (compared with 7 per cent when there is one restriction). Under ten restrictions the length of the identified set is 36 per cent shorter, on average, than under the baseline sign restrictions.
Appendix C: Additional Details about Empirical Exercises
This appendix provides additional details related to the empirical applications. Appendix C.1 describes the numerical procedures used to approximate identified sets in both applications. I then revisit two exercises from LMN using the shock-percentile restrictions: Appendix C.2 examines whether recursive identification schemes are consistent with the data; and Appendix C.3 examines whether the structural shocks are non-Gaussian.
C.1 Numerical implementation
To approximate identified sets in Section 5, I obtain draws of Q from (an approximation of) the uniform distribution over its identified set, compute the parameters of interest, and take the minimum and maximum of the parameter over the draws of Q.[42] Given a finite number of draws, this strategy will generate identified sets that are too narrow, with the approximation error vanishing as the number of draws increases. As discussed in Section B.1, Montiel Olea and Nesbit (2021) provide results about the number of draws required to guarantee a given degree of approximation error. Based on the upper bound in their Theorem 3, approximating an identified set of dimension d = 3 × 3 × 61 = 549 with misclassification error less than and probability at least requires draws from inside the identified set.
Under the event and external variable constraints considered in LMN, the identified set for Q is substantially truncated relative to the unconstrained identified set. Obtaining a sufficient number of draws satisfying the restrictions via accept-reject sampling is consequently extremely computationally burdensome. I therefore use the sampler based on ‘soft sign restrictions’ proposed in Read and Zhu (2025), which can be more computationally efficient than accept-reject sampling in cases like this where identification is ‘tight’.
The sampler uses Markov chain Monte Carlo methods (specifically, the slice sampler) to obtain draws of Q from a target distribution that is similar to the uniform distribution but that smoothly penalises parameter values that violate the identifying restrictions. This yields some draws that violate the restrictions, and draws that satisfy the restrictions are not uniformly distributed. An importance-sampling step can be used to discard the draws that violate the restrictions and resample the remaining draws so that they better approximate the target uniform distribution. However, since the objective here is only to approximate the bounds of the identified set, it suffices to discard the draws that violate the identifying restrictions, leaving only draws from inside the identified set, and the resampling step is unnecessary. Otherwise, the implementation of the sampler follows Read and Zhu (2025).[43]
To obtain L effective draws from inside the identified set, it is necessary to obtain more than L draws from the smoothed target density, because some draws will not satisfy the identifying restrictions. For each set of identifying restrictions, I therefore gross up L by an initial estimate of the effective sample size for the sampler. For example, under the restrictions from LMN, the effective sample size is around 89 per cent, so I obtain L/0.89 draws, which yields approximately L draws from inside the identified set.
To implement the robust Bayesesian approach to inference in the empirical application in Section 6, I use the same approach to approximating identified sets at each draw of the reduced-form parameters. Based on the upper bound from Theorem 3 of Montiel Olea and Nesbit (2021), approximating an identified set of dimension d = 2 × 61 = 122 with misclassification error less than and probability at least requires draws of Q at each draw of the reduced-form parameters.[44] The results are based on 1,000 draws of the reduced-form parameters.
C.2 Recursive identification
Much of the empirical literature on the macroeconomic effects of uncertainty relies on recursive identifying schemes to estimate the effects of uncertainty shocks.[45] LMN demonstrate that recursive structures are inconsistent with their results. This section examines whether this remains the case when replacing the shock-magnitude restrictions with shock-percentile restrictions.
There are three variables in the SVAR, so there are 3! = 6 possible recursive orderings. Let
so Hij is the impact response of variable i to shock j. The six possible recursive orderings are:
At a given value of , we can assess whether a specific recursive ordering is consistent with the data and identifying restrictions by: 1) computing the (point-identified) structural parameters under the recursive ordering; and 2) checking whether the event and external variable constraints are satisfied (i.e. that the identified set is non-empty).[46] If none of the structural parameters implied by the six recursive orderings are consistent with the event and external variable constraints, recursive structures are inconsistent with the data (given the other identifying restrictions).
At the OLS estimates of , none of the possible recursive orderings are consistent with the event and external variable constraints used in LMN. This continues to be the case when replacing the shock-magnitude restrictions with the shock-percentile restrictions (with ). This suggests that recursive orderings are not supported by the data, conditional on the other identifying restrictions. The results under the shock-percentile restrictions therefore reinforce the challenges associated with relying on recursive assumptions when attempting to tease apart the causal relationship between uncertainty and real activity.[47]
C.3 Are the shocks non-Gaussian?
Focusing on a particular set of parameters within the identified set, LMN document that the implied structural shocks exhibit features of non-Gaussianity, such as skewness and excess kurtosis. This result may be of interest because researchers often assume that structural shocks are normally distributed when using Bayesian methods to estimate SVARs, and departures from Gaussianity can distort inference (e.g. Petrova 2022). This section examines whether evidence of non-Gaussianity remains under the shock-percentile restrictions.
Rather than focusing on the properties of a single sequence of shocks implied by a particular set of parameters, as in LMN, I compute identified sets for the skewness and kurtosis of each structural shock. Intuitively, each Q in the identified set is associated with a different sequence of shocks, and thus (potentially) a different skewness and kurtosis. I characterise identified sets for the skewness and kurtosis of the shocks by randomly drawing values of Q from the uniform distribution over , computing the skewness and kurtosis of the implied shocks, and taking the minimum and maximum of these statistics over the draws of Q.[48]
Table C1 presents identified sets for the skewness and kurtosis of the structural shocks under the identifying restrictions from LMN and the shock-percentile restrictions with . If the shocks were Gaussian, we should expect them to have skewness equal to zero and kurtosis equal to three. The identified sets under the LMN restrictions unambiguously point to the presence of non-Gaussian features in the identified shocks; macroeconomic uncertainty shocks are positively skewed, output and financial uncertainty shocks are negatively skewed, and all shocks display excess kurtosis.
| Shock | Skewness | Kurtosis | |||
|---|---|---|---|---|---|
| LMN | SP(a) | LMN | SP(a) | ||
| [0.30, 0.56] | [−0.70, 0.56] | [5.56, 5.90] | [5.34, 10.63] | ||
| [−0.47, −0.28] | [−1.01, −0.03] | [5.38, 5.97] | [4.84, 11.03] | ||
| [−1.69, −1.48] | [−1.88, 0.11] | [16.87, 19.16] | [7.33, 20.95] | ||
|
Note: (a) ‘SP’ corresponds to shock-percentile restrictions with |
|||||
While the identified sets under the shock-percentile restrictions are wider than under the LMN restrictions, they continue to suggest that the structural shocks possess some non-Gaussian features. The identified sets for skewness contain zero for the uncertainty shocks and values close to zero for the output shock, so there is no longer clear evidence of skewness in the identified shocks. However, the identified sets unambiguously point to excess kurtosis in all three shocks.
References
Abbate A, S Eickmeier and E Prieto (2023), ‘Financial Shocks and Inflation Dynamics’, Macroeconomic Dynamics, 27(2), pp 350–378.
Andrade P, F Ferroni and L Melosi (2024), ‘Higher-order Moment Inequality Restrictions for SVARs’, Centre for Economic Policy Research Discussion Paper DP19813.
Andreasen MM, G Caggiano, E Castelnuovo and G Pellegrino (2024), ‘Does Risk Matter More in Recessions than in Expansions? Implications for Monetary Policy’, Journal of Monetary Economics, 143, Article 103533.
Angelini G, E Bacchiocchi, G Caggiano and L Fanelli (2019), ‘Uncertainty across Volatility Regimes’, Journal of Applied Econometrics, 34(3), pp 437–455.
Antolín-Díaz J and JF Rubio-Ramírez (2018), ‘Narrative Sign Restrictions for SVARs’, The American Economic Review, 108(10), pp 2802–2829.
Arias JE, JF Rubio-Ramírez and DF Waggoner (2018), ‘Inference Based on Structural Vector Autoregressions Identified with Sign and Zero Restrictions: Theory and Applications’, Econometrica, 86(2), pp 685–720.
Arias JE, JF Rubio-Ramírez and DF Waggoner (2025), ‘Uniform Priors for Impulse Responses’, Econometrica, 93(2), pp 695–718.
Baker SR, N Bloom and SJ Terry (2024), ‘Using Disasters to Estimate the Impact of Uncertainty’, The Review of Economic Studies, 91(2), pp 720–747.
Baumeister C and JD Hamilton (2015), ‘Sign Restrictions, Structural Vector Autoregressions, and Useful Prior Information’, Econometrica, 83(5), pp 1963–1999.
Baumeister C and JD Hamilton (2018), ‘Inference in Structural Vector Autoregressions when the Identifying Assumptions Are Not Fully Believed: Re-evaluating the Role of Monetary Policy in Economic Fluctuations’, Journal of Monetary Economics, 100, pp 48–65.
Baumeister C and JD Hamilton (2019), ‘Structural Interpretation of Vector Autoregressions with Incomplete Identification: Revisiting the Role of Oil Supply and Demand Shocks’, The American Economic Review, 109(5), pp 1873–1910.
Baumeister C and JD Hamilton (2024), ‘Advances in Using Vector Autoregressions to Estimate Structural Magnitudes’, Econometric Theory, 40(3), pp 472–510.
Ben Zeev N (2018), ‘What Can We Learn about News Shocks from the Late 1990s and Early 2000s Boom-bust Period?’, Journal of Economic Dynamics & Control, 87, pp 94–105.
Bloom N (2009), ‘The Impact of Uncertainty Shocks’, Econometrica, 77(3), pp 623–685.
Braun R (2023), ‘The Importance of Supply and Demand for Oil Prices: Evidence from Non-Gaussianity’, Quantitative Economics, 14(4), pp 1163–1198.
Brianti M (2025), ‘Financial Shocks, Uncertainty Shocks, and Corporate Liquidity’, Journal of Applied Econometrics, 40(7), pp 814–828.
Caggiano G and E Castelnuovo (2023), ‘Global Financial Uncertainty’, Journal of Applied Econometrics, 38(3), pp 432–449.
Caggiano G, E Castelnuovo and N Groshenny (2014), ‘Uncertainty Shocks and Unemployment Dynamics in U.S. Recessions’, Journal of Monetary Economics, 67, pp 78–92.
Caggiano G, E Castelnuovo and R Kima (2020), ‘The Global Effects of Covid-19-induced Uncertainty’, Economics Letters, 194, Article 109392.
Caggiano G, E Castelnuovo, R Kima and S Delrio (2020), ‘Financial Uncertainty and Real Activity: The Good, the Bad, and the Ugly’, Australian National University Crawford School of Public Policy, Centre for Applied Macroeconomic Analysis, CAMA Working Paper 67/2020.
Carriero A, M Marcellino and T Tornese (2023), ‘Macro Uncertainty in the Long Run’, Economics Letters, 225, Article 111067.
Ferreira LN (2022), ‘Forward Guidance Matters: Disentangling Monetary Policy Shocks’, Journal of Macroeconomics, 73, Article 103423.
Fry R and A Pagan (2011), ‘Sign Restrictions in Structural Vector Autoregressions: A Critical Review’, Journal of Economic Literature, 49(4), pp 938–960.
Giacomini R and T Kitagawa (2021a), ‘Robust Bayesian Inference for Set-identified Models’, Econometrica, 89(4), pp 1519–1556.
Giacomini R and T Kitagawa (2021b), ‘Supplement to “Robust Bayesian Inference for Set-identified Models”’, Econometrica, 89(4), Supporting Information, Online Appendix.
Giacomini R, T Kitagawa and M Read (2021), ‘Identification and Inference under Narrative Restrictions’, Unpublished manuscript, February. Available at <https://doi.org/10.48550/arXiv.2102.06456>.
Giacomini R, T Kitagawa and M Read (2023), ‘Identification and Inference under Narrative Restrictions’, RBA Reseach Discussion Paper No 2023-07.
Himounet N (2022), ‘Searching the Nature of Uncertainty: Macroeconomic and Financial Risks VS Geopolitical and Pandemic Risks’, International Economics, 170, pp 1–31.
Inoue A and L Kilian (2025), ‘The Conventional Impulse Response Prior in VAR Models with Sign Restrictions’, Centre for Economic Policy Research Discussion Paper DP20159.
Inoue A and L Kilian (2026), ‘When Is the Use of Gaussian-inverse Wishart-Haar Priors Appropriate?’, Journal of Political Economy, 134(2), pp 773–794.
Jurado K, SC Ludvigson and S Ng (2015), ‘Measuring Uncertainty’, The American Economic Review, 105(3), pp 1177–1216.
Kang S and K Park (2024), ‘Endogenous Uncertainty and Monetary Policy’, Macroeconomic Dynamics, 28(2), pp 462–477.
Kilian L and H Lütkepohl (2017), Structural Vector Autoregressive Analysis, Themes in Modern Econometrics, Cambridge University Press, Cambridge.
Kilian L, MD Plante and AW Richter (2025), ‘Macroeconomic Responses to Uncertainty Shocks: The Perils of Recursive Orderings’, Journal of Applied Econometrics, 40(4), pp 395–410.
Lanne M, M Meitz and P Saikkonen (2017), ‘Identification and Estimation of Non-Gaussian Structural Vector Autoregressions’, Journal of Econometrics, 196(2), pp 288–304.
Leduc S and Z Liu (2016), ‘Uncertainty Shocks Are Aggregate Demand Shocks’, Journal of Monetary Economics, 82, pp 20–35.
Lowenstein R (2000), When Genius Failed: The Rise and Fall of Long-Term Capital Management, Random House, New York.
Ludvigson SC, S Ma and S Ng (2017), ‘Shock Restricted Structural Vector-autoregressions’, NBER Working Paper No 23225, rev January 2020.
Ludvigson SC, S Ma and S Ng (2021), ‘Uncertainty and Business Cycles: Exogenous Impulse or Endogenous Response?’, American Economic Journal: Macroeconomics, 13(4), pp 369–410.
Manski CF (2003), Partial Identification of Probability Distributions, Springer Series in Statistics, Springer-Verlag, New York.
Manski CF (2011), ‘Policy Analysis with Incredible Certitude’, The Economic Journal, 121(554), pp F261–F289.
Mertens K and MO Ravn (2013), ‘The Dynamic Effects of Personal and Corporate Income Tax Changes in the United States’, The American Economic Review, 103(4), pp 1212–1247.
Montiel Olea JL and J Nesbit (2021), ‘(Machine) Learning Parameter Regions’, Journal of Econometrics, 221(1, Part C), pp 716–744.
Moon HR and F Schorfheide (2012), ‘Bayesian and Frequentist Inference in Partially Identified Models’, Econometrica, 80(2), pp 755–782.
Petrova K (2022), ‘Asymptotically Valid Bayesian Inference in the Presence of Distributional Misspecification in VAR Models’, Journal of Econometrics, 230(1), pp 154–182.
Poirier DJ (1998), ‘Revising Beliefs in Nonidentified Models’, Econometric Theory, 14(4), pp 483–509.
Ramey VA (2016), ‘Macroeconomic Shocks and Their Propagation’, in JB Taylor and H Uhlig (eds), Handbook of Macroeconomics: Volume 2A, Handbooks in Economics, Elsevier, Amsterdam, pp 71–162.
Read M (2022), ‘Algorithms for Inference in SVARs Identified With Sign and Zero Restrictions’, The Econometrics Journal, 25(3), pp 699–718.
Read M (2024), ‘Sign Restrictions and Supply-demand Decompositions of Inflation’, RBA Research Discussion Paper No 2024-05.
Read M (forthcoming), ‘Set-identified Structural Vector Autoregressions and the Effects of a 100 Basis Point Monetary Policy Shock’, The Review of Economics and Statistics.
Read M and D Zhu (2025), ‘Fast Posterior Sampling in Tightly Identified SVARs Using “Soft” Sign Restrictions’, RBA Research Discussion Paper No 2025-03.
Romer CD and DH Romer (1989), ‘Does Monetary Policy Matter? A New Test in the Spirit of Friedman and Schwartz’, in OJ Blanchard and S Fischer (eds), NBER Macroeconomics Annual 1989, 4, The MIT Press, Cambridge, pp 121–170.
Rubio-Ramírez JF, DF Waggoner and T Zha (2010), ‘Structural Vector Autoregressions: Theory of Identification and Algorithms for Inference’, The Review of Economic Studies, 77(2), pp 665–696.
Stock JH and MW Watson (2018), ‘Identification and Estimation of Dynamic Causal Effects in Macroeconomics Using External Instruments’, The Economic Journal, 128(610), pp 917–948.
Theophilopoulou A (2022), ‘The Impact of Macroeconomic Uncertainty on Inequality: An Empirical Study for the United Kingdom’, Journal of Money, Credit and Banking, 54(4), pp 859–884.
Uhlig H (2005), ‘What Are the Effects of Monetary Policy on Output? Results from an Agnostic Identification Procedure’, Journal of Monetary Economics, 52(2), pp 381–419.
Uhlig H (2017), ‘Shocks, Sign Restrictions, and Identification’, in B Honoré, A Pakes, M Piazzesi and L Samuelson (eds), Advances in Economics and Econometrics: Eleventh World Congress: Volume 2, Econometric Society Monographs, Cambridge University Press, Cambridge, pp 95–127.
Watson MW (2020), ‘Comment on “On the Empirical (Ir)relevance of the Zero Lower Bound”’, in MS Eichenbaum, E Hurst and JA Parker (eds), NBER Macroeconomics Annual 2019, 34, University of Chicago Press, Chicago, pp 182–193.
Acknowledgements
For helpful comments, I thank Efrem Castelnuovo, Jarkko Jääskelä, Gabriela Nodari, participants at the 2025 Workshop of the Australasian Macroeconomics Society, the 2025 OzMac Workshop and the Inaugural AE2 Conference, and seminar participants at the University of Sydney and the Reserve Bank of Australia. I am particularly grateful to James Morley for discussing the paper at the Inaugural AE2 Conference. The views expressed in this paper are those of the author and should not be attributed to the Reserve Bank of Australia. Any errors are the sole responsibility of the author.
Footnotes
Several papers employ shock-magnitude restrictions to help identify uncertainty shocks, including Caggiano, Castelnuovo and Kima (2020), Caggiano et al (2020), Himounet (2022), Theophilopoulou (2022), Caggiano and Castelnuovo (2023), Carriero, Marcellino and Tornese (2023), Baker, Bloom and Terry (2024) and Kang and Park (2024). Shock-magnitude restrictions have also been used in other settings. For example, they are applied by Ludvigson et al (2017) in models of the global oil market and US monetary policy, and by Ferreira (2022) to disentangle forward guidance and conventional monetary policy shocks. [1]
Arias, Rubio-Ramírez and Waggoner (2025) show that the uniform prior for the orthonormal matrix induces a joint uniform prior over the vector of impulse responses. [2]
Section 3.3 argues that a Bayesian analogue of this bound-elicitation procedure would also be problematic. [3]
Shock-percentile restrictions are not necessarily always weaker than comparable shock-magnitude restrictions. See Section 5.2.3 for further discussion. [4]
I abstract from the inclusion of a constant for simplicity. [5]
For definitions of impulse responses and FEVDs, see Kilian and Lütkepohl (2017). [6]
Similar arguments have been made in other settings. For example, Ramey (2016) argues that the recursive orderings commonly used when identifying the effects of monetary policy have little theoretical motivation. [7]
When the identifying restrictions include event constraints (or narrative restrictions), the restrictions depend on the realisation of the data via the reduced-form innovations, ut. This means the standard definition of an identified set as the set of observationally equivalent parameters does not apply. In settings like this, Giacomini et al (2023) introduce a refinement of the identified set – a ‘conditional identified set’ – that describes the data-dependent mapping from reduced-form parameters to the structural object of interest. For ease of exposition, I do not distinguish between conditional identified sets and identified sets. [8]
Given the normalisation that is measured in standard deviations. [9]
Ludvigson, Ma and Ng (2017) discuss how shock-magnitude restrictions can provide identifying information. [10]
Angelini et al (2019) consider the same model, but identify shocks by exploiting breaks in the volatility of macroeconomic variables. [11]
These identified sets can be characterised by their end points. depends on Q only via qj. The unconstrained identified set for qj is given by the intersection of the unit sphere in and the half-space , which is path-connected. Since is a continuous function of qj on a path-connected domain, the set of function values on this domain is an interval. This argument follows the same reasoning as in Giacomini and Kitagawa (2021a, 2021b), who provide conditions for convexity of impulse-response identified sets. I approximate these sets by taking the minimum and maximum of over the 1.5 million draws of Q from . [12]
While there has been debate about the desirability of using such a prior, it nevertheless remains a well-defined prior distribution. For different sides of this debate, see Baumeister and Hamilton (2018, 2019, 2024), Watson (2020), Arias et al (2025) and Inoue and Kilian (2025, 2026). [13]
In the example above, the unconstrained identified set for is [0.43, 0.64]. [14]
If , then , where and H0 is the true value of H. Since the reduced-form parameters are point identified, we can consider setting , and . Since Q is orthonormal, it follows that for any . [15]
For approaches to identifying SVARs that exploit non-Gaussianity of shocks see, for example, Lanne, Meitz and Saikkonen (2017), Braun (2023) and Andrade, Ferroni and Melosi (2024). [16]
I assume Gaussian shocks here for simplicity, but none of the qualitative results substantively depend on this assumption. [17]
See Baumeister and Hamilton (2015) or Read (2024) for a characterisation of this identified set. [18]
The data-generating process underlying this exercise assumes that vec(H) = (1,–0.3, 0.2, 1.2)’, which implies that pt and qt are weakly negatively correlated. [19]
See Appendix B.1 for details about how this Monte Carlo exercise is implemented. [20]
The event constraints proposed in LMN and Ludvigson et al (2017) can also be viewed as narrative restrictions, though they were proposed independently. [21]
The restriction that a shock was the largest realisation of that shock over the sample period is nested within (9) when . Restrictions on the absolute values of shocks can be implemented by replacing the shocks with their absolute values in (7) and (9). [22]
LMN use a bootstrap to account for sampling uncertainty in one exercise (see their Figure 6), though the theoretical properties of their bootstrap are unknown. Section 6 presents an additional empirical application in which I account for sampling uncertainty using a prior-robust Bayesian method. [23]
S1t is the Center for Research in Security Prices value-weighted stock market index return. S2t is the log difference in the real price of gold (deflated using the US Consumer Price Index). See LMN for details about how these variables are constructed. [24]
Under the identifying restrictions, it is not guaranteed that identified sets for the parameters of interest are convex. If the identified sets are non-convex, the interval estimates presented below can be interpreted as estimating convex hulls of identified sets. See Giacomini and Kitagawa (2021a, 2021b) for sufficient conditions under which impulse-response identified sets are convex. [25]
This contrasts with the treatment in LMN, who obtain 1.5 million draws of Q from and approximate identified sets using only those draws that satisfy the identifying restrictions; for example, the identified sets under the event and external variable constraints described above are approximated using the 169 draws that satisfy the restrictions. [26]
The estimated identified sets are very similar to those presented in LMN, though they are slightly wider, reflecting the larger number of draws used to approximate identified sets and the consequent reduction in approximation error. [27]
LMN also motivate the timing of their shock-magnitude restrictions based on the RWZ algorithm, which could be problematic when the identified timing of large shocks depends on the distribution for Q. For example, the identified set for consists of (at least) 13 different months, so the period where the largest financial uncertainty shock occurred is not pinned down by the data. However, the timing of the restrictions is additionally motivated using narrative information. I therefore proceed under the assumption that the timing of these restrictions is credible. [28]
Appendices C.2 and C.3 apply the shock-percentile restrictions to revisit additional empirical questions considered in LMN. Appendix C.2 reaffirms the results in LMN that the data are inconsistent with recursive identification schemes, which have been widely used to identify uncertainty shocks. Appendix C.3 presents evidence that the structural shocks possess non-Gaussian features, which is inconsistent with the common Gaussianity assumption in Bayesian SVARs. [29]
Let Hi,j,t be the contribution of shock j to the one-step-ahead forecast error in variable i in period t. The restriction that the first shock was the ‘overwhelming contributor’ to variable i in period t is and the restriction that it was the ‘most important contributor’ to variable i in period t is . [30]
Giacomini et al (2021) and Read (2022) impose the ‘shock-ranking’ restriction that the monetary policy shock in the Volcker episode was the largest absolute realisation of the shock in the sample period, which is stronger than the shock-percentile restriction considered here. [31]
See Appendix C.1 for details about how the approach to inference is implemented numerically. [32]
The estimates under the Volcker restrictions from AR18 coincide with those presented in the Online Appendix to Read (forthcoming). The results presented here are not directly comparable to those in AR18, because the impulse responses are normalised differently. [33]
An alternative (more tedious) way to show this is to explicitly characterise the conditional identified set. Since is an interval and is a continuous function of is also an interval, so it can be characterised by its end points. The bounds of occur either at the end points of or at a critical point of in the interior of We could therefore characterise the bounds of by comparing the values of evaluated at the critical point and the end points. [35]
The sign normalisations on the remaining columns of Q do not constrain q1; given any we can always iteratively construct the remaining columns of Q such that they are orthogonal to q1 (and each other) and satisfy the sign normalisations. [36]
This result closely parallels Proposition 3.2 in Read (forthcoming), who derives a sufficient condition under which impulse-response identified sets include zero when there are sign and zero restrictions on a single column of Q. [37]
This exercise assumes that Given the value of H in the DGP, this implies that [38]
For a characterisation of the identified set under these restrictions, see Baumeister and Hamilton (2015) or Read (2024). [39]
Draws of Q are transformed into draws of via where [40]
It is well-known that the strength of the correlation between price and quantity innovations influences the sharpness of identification in this model of supply and demand. For example, see Uhlig (2017) or Read (2024). [41]
This approach follows Algorithm 2 in Giacomini and Kitagawa (2021a). [42]
The sampler from Read and Zhu (2025) requires specifying a tuning parameter that determines how strongly parameter values are penalised when they violate the identifying restrictions. I set . [43]
I present identified sets for the responses of two variables (the federal funds rate and output) for horizons h = 0, 1,..., 60. Approximating identified sets for the responses of additional variables with the same degree of accuracy would require more draws of Q. [44]
See Kilian, Plante and Richter (2025) for many examples. [45]
LMN check whether the identified sets for the relevant elements of H exclude zero, which is a sufficient condition for the identified sets to be inconsistent with a recursive ordering. [46]
Kilian et al (2025) demonstrate that this challenge can not be overcome by examining the results obtained under alternative causal orderings, because these do not necessarily bound the true impulse responses when the DGP does not feature a recursive structure. [47]
A similar idea underlies the approach to identification in Andrade et al (2024). Given that higher-order moments are set identified under sign restrictions, they impose inequality constraints on higher-order moments to sharpen identification. [48]