RDP 2025-06: An AI-powered Tool for Central Bank Business Liaisons: Quantitative Indicators and On-demand Insights from Firms 3. Solution Architecture
August 2025
The solution architecture underpinning our new liaison-based text analytics and information retrieval tool was designed in close (and ongoing) collaboration between data scientists and economists from the RBA's liaison team. At a high level, staff from the liaison team wanted a tool to help them in three broad areas. First, to be able to answer additional ad hoc requests from senior decision-makers more comprehensively, such as, ‘what have we been hearing lately about topic X in industry Y?’ Second, the ability to place information within a historical context and to synthesise available information more efficiently. Third, to improve the ability to quickly extract signals from liaison text and communicate them more effectively. In this section, we outline the components of the solution and how they come together to achieve these desired objectives. We begin by outlining how the text of a liaison meeting is generated (the data-generating process) before detailing our text extraction, pre-processing and enrichment steps.
3.1 The data-generating and enrichment processes
Over the life of the liaison program, details of each of the RBA's 22,000 liaisons have been systematically recorded in two information management systems (Figure 2):
- The first is the client relationship management (CRM) database. When a liaison has been conducted, the occurrence of the meeting is recorded in the CRM. This record includes information such as the contact date, metadata about the business (name, industry, etc), attendees and any staff scores associated with the meeting as discussed in Section 2.
- The second is the RBA's file management system (FMS), which is where staff save a confidential written summary of each liaison meeting. After drafting the summary according to a pre-defined template, the detailed summaries are reviewed by an editor, who also attended the liaison meeting, and added to the FMS. About one-third of the summaries are completed within two days of the liaison meeting (with this share increasing in the lead up to Monetary Policy Board meetings) and most are completed within a week. A unique identifier is generated when a liaison is saved in the FMS and is also added to the CRM database.
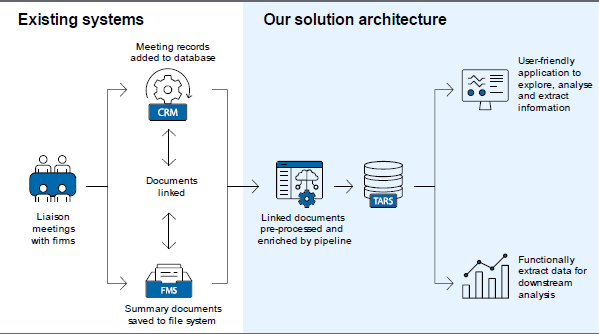
The unique liaison identifiers provide a critical link between these two information management systems, which together form the backbone of our business intelligence text analytics and retrieval system (TARS). To build the TARS, liaison summaries are extracted and cleaned using a text pre-processing and enrichment pipeline, which does the following:
- First, liaison summaries are identified and programmatically extracted from the FMS by looking up their unique identifiers as recorded in the CRM.
- Next, all text summaries are converted to an extensible markup language (.xml) format. This format is useful for several reasons. It is interoperable, meaning the text can be easily shared and processed across different systems and platforms. It also encodes styles inherited from the original text document (e.g. .doc or .docx) such as headings, paragraphs, and other formatting elements. We use these encoded text styles in combination with a set of heuristics to tag each component of each liaison summary as either a ‘HEADING’, ‘BODY’, ‘TABLE’ or ‘UNKNOWN’.[5] ‘BODY’ text chunks include bulleted dot points and paragraphs, both of which will be referred to as paragraphs going forward.
- Text identified as paragraphs is then enriched with NLP-generated tags. These tags include information about the topic being discussed in the paragraph (e.g. ‘wages’) and the associated tone of the discussion. We also use NLP techniques to extract precise numerical information from the paragraph, such as expected growth in wages or prices over the year ahead. Further details of these NLP methods are outlined in the next section.
- Finally, each enriched paragraph and its associated tags are uploaded into a relational database indexed at a paragraph level. In addition to the NLP-generated tags, every paragraph is also tagged with all the metadata about the liaison meeting as recorded in the CRM.
The initial synthesis of the large corpus of liaison text into a searchable database required an intensive extraction of historical records from the FMS. The challenging task of recalling and extracting information from documents up to 25 years old was feasible thanks to the stable, centralised record-keeping processes that have been consistently followed by the liaison team.[6]
3.2 Extracting information
Our final TARS database provides the ability for liaison officers to retrieve information quickly and efficiently from the full corpus of liaison intelligence. Insights from these data can be retrieved through a user-friendly application that does not require any coding skills. This makes our TARS accessible to the whole liaison team. In addition to the front-end application, the data can be extracted using several coding languages for more bespoke analytics and requests. The result is that the full corpus of liaison text can be filtered, analysed, and retrieved within seconds.
To keep the TARS database up to date, liaison records are continually added and updated in the CRM and the FMS, which are picked up by a nightly update of the TARS database. This ensures the most up-to-date information about firms is always available for extraction from the tool.
Footnotes
These heuristics were developed in close consultation with subject matter experts from the business liaison team with intimate knowledge about how the liaison summaries are written. [5]
However, as with any legacy data entry system, there were cases where the identifier for the document was incorrect or incomplete. Most cases of non-matches occurred in the first few years of the program. Using fuzzy matching of the file identifier, contact name and date to the full list of documents in relevant folders of the FMS increased the matching rate. This notwithstanding, caution should be adopted when using information extracted from the tool prior to 2008. [6]