RDP 2013-04: Home Prices and Household Spending 3. Methodology
April 2013 – ISSN 1320-7229 (Print), ISSN 1448-5109 (Online)
- Download the Paper 732KB
To study the nature of home-price wealth effects, we use the HILDA panel and the framework proposed by Attanasio and Weber (1994) (see also Campbell and Cocco (2007) and Attanasio et al (2009)). Specifically, we estimate home-price wealth effects by examining how the value of goods and services consumed by households responds to changes in home prices, controlling for a number of other factors such as education levels and income. Further, we split households up into young, middle and old households in order to examine differences in wealth effects between age groups. The estimation is performed using a panel regression where each household's home price and spending level is tracked through time.
The main advantage of our study over previous studies is that we use an actual panel rather than a pseudo-panel of birth cohorts constructed from a series of cross-sections. This enables us to move by degrees – from household-level data to cohort-level data – by first tracking the same households through time and then tracking the same ‘cohorts’ (defined as a group of households with fixed membership) through time. By doing so, any differences in results due to different levels of data aggregation can be identified.
The appeal of Attanasio and Weber's (1994) framework is the lack of structure it imposes upon empirically estimated relationships, though it can be seen as an approximation to the life-cycle model. The life-cycle model predicts that real spending is equal to an annuity value of lifetime resources and its interaction with the life-cycle of the household:
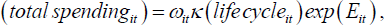
where total spendingit is real annual spending of household i at time t, and ωit is some fraction of total wealth that includes, for instance, financial wealth and housing wealth. The function κ (lifecycleit) captures the age and composition of household members. What is left unexplained, exp(Eit), is unexplained variation in lifetime earnings including temporary shocks/measurement error in current earnings. Taking logs of the above equation yields:
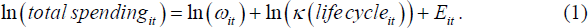
Equation (1) can be estimated using proxies for log lifetime wealth ln(ωit) and for the life-cycle function ln (κ(lifecycleit)) as per Equation (2):
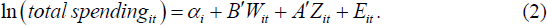
Log lifetime wealth is proxied with the constant αi and a vector of variables, Wit, which includes: dummy variables for the highest level of education achieved by the household head;[8] the occupational classification of the household head; the log of real financial asset holdings, FAit;[9] and the log of real disposable income, HHDYit (we also include the log of real housing wealth, detailed below, but for presentational purposes we consider it separately from the other wealth variables contained in Wit). The coefficients in vector B will represent a log-level shift in spending for changes in categorical variables and, for the continuous variables, the elasticity of spending. The life-cycle function is proxied with a vector of variables, Zit, including: the number of adults and the number of children in the household; a dummy for households with three or more adult members; labour force status of the household head; and region of residence.
The impact of changes in real home prices on spending is the key focus of this paper. A variable that we can use to estimate this home-price wealth effect is constructed in several stages.
First we estimate unexplained movements in home prices as the residual from a self-reported home-price regression:
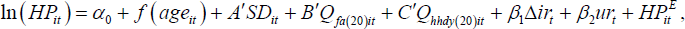
where HPit are self-reported home prices from
HILDA;[10]
SDit
denotes the statistical sub-division where household i resides at
time t (130 such sub-divisions are present in panel two, for example);
Qfa(20)it is a vector of dummies for
financial asset vigintile; Qhhdy(20)it
is a vector of dummies for household disposable income vigintile; Δirt
is the percentage point change in nominal average outstanding lending rates
between time t − 1 and time t; urt
is the unemployment rate at time t; and 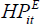 is the residual or
unexplained component of home prices. Regression outputs for panel two are
given in Table B1. This regression fits the data well, with an R2
of over 50 per cent. Much of the explanatory power comes from the regional dummy
variables capturing a range of characteristics associated with the home location,
including the amenities in the region and the average quality of housing in
the
area.[11]
is the residual or
unexplained component of home prices. Regression outputs for panel two are
given in Table B1. This regression fits the data well, with an R2
of over 50 per cent. Much of the explanatory power comes from the regional dummy
variables capturing a range of characteristics associated with the home location,
including the amenities in the region and the average quality of housing in
the
area.[11]
Second, the variable is interacted with a vector of dummies,
Agei, indicating the age group of the household head in
the first survey year as either young (23 to 35 years), middle (36 to 50 years)
or old (over
50 years).
It is the existence, or lack thereof, of differences in home-price wealth effects across different age groups that will allow us to distinguish between the various hypotheses put forward for the cause of these wealth effects. Larger wealth effects for older homeowners would be consistent with a traditional wealth effect, while larger wealth effects for younger homeowners could reflect credit constraints and/or common factors.
To examine the relative merit of these latter two explanations, the panel including
renters is considered (panel one in
Table 1), a renter dummy is added, and the term 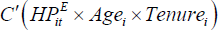 is added to the baseline
model, where
Tenurei is a dummy variable indicating the home tenure
type of the household. If home-price wealth effects are due to common factors
then consumption should increase for young renters as well as young homeowners
following a positive home-price shock. If these effects are due to credit constraints
then the consumption of young homeowners should again increase, but the consumption
of young renters should not.
is added to the baseline
model, where
Tenurei is a dummy variable indicating the home tenure
type of the household. If home-price wealth effects are due to common factors
then consumption should increase for young renters as well as young homeowners
following a positive home-price shock. If these effects are due to credit constraints
then the consumption of young homeowners should again increase, but the consumption
of young renters should not.
For ease of interpretation, we present results in Section 4 in a form that is comparable to the aggregate MPCs discussed in the introduction and commonly referred to in the literature. Estimated elasticities for each age group are converted to MPCs by multiplying the elasticities by the sample average ratio of non-housing consumption to dwelling wealth over the period 2003 to 2010 for each age group.[12]
Finally, as shown in Table 1, to aid the interpretation of our results we exclude a number of households from our panels. This may result in selection bias. For example, restricting the sample to households that maintained their tenure type over the period 2003 to 2010 could result in selection bias if, for example, homeowners who maintain the same tenure type over a long period have smaller wealth effects because they are less likely to be aware of fluctuations in home prices. To detect possible selection bias in a panel data model with fixed effects, we perform Wooldridge's (1995) variable addition test. This involves estimating a pooled probit (across all i and t) on same-tenure and changing-tenure households, and calculating the inverse Mills ratio (IMR) for the likelihood of maintaining the same tenure type over eight years.[13] The IMR is then added to Equation (2) and the model estimated using both same-tenure and changing-tenure households. The significance or otherwise of the coefficient on the IMR indicates whether there are sample selection issues. The IMR was found to be insignificant, indicating that sample selection is not biasing our results.[14]
Footnotes
Education is generally considered to be an effective proxy for permanent income. Attanasio and Weber (2010), for instance, document that more highly educated households tend to have higher (and steeper) income profiles than those headed by less educated individuals. [8]
Self-reported household financial assets are only available from the HILDA wealth modules of 2006 and 2010. Accordingly, financial wealth was imputed for every household in years 2003 to 2005 and 2007 to 2009. To perform the imputation, a linear trend was interpolated for all households' financial assets between wealth module years. Household-level financial assets were then shifted about this trend according to the annual percentage point deviation of the ABS aggregate household sector financial asset series from its trend. [9]
The use of self-reported home prices – given their availability in the dataset – are an obvious choice over independent data from dwelling-price providers; ultimately it is self-reported ‘perceived’ home prices that should matter for household-level spending decisions. [10]
Under the traditional wealth effects hypothesis it is unexplained or unanticipated changes in the value of wealth that induce households to spend more or less each period. Moreover, a household's perceived buffer-stock saving level is more likely to be affected by unanticipated changes in home prices rather than anticipated changes. These conceptual arguments notwithstanding, our results do not change greatly if we use actual self-reported home values instead of their unanticipated components (see Model 1 in Table C1). [11]
These ratios are 0.2, 0.18 and 0.13 for young, middle and old age groups respectively. [12]
All regressors from Equation (2) were included in the probit plus current and prospective job security/worries and the ability to raise cash in an emergency (results are available upon request). [13]
Correcting for selection bias in panel data models is not as straightforward as detecting selection bias. This point notwithstanding, and despite failing to reject the null of no selection bias, we examined results using a correction for the likelihood of maintaining home tenure type (Wooldridge 1995). The qualitative results were unchanged. [14]