RDP 2003-09: Housing Leverage in Australia 2. The HILDA Dataset
July 2003
- Download the Paper 605KB
In this study we use data from the Household, Income and Labour Dynamics in Australia (HILDA) Survey. HILDA is a household-based panel or longitudinal survey that aims to track all members of an initial sample of Australian households over time. The survey was commissioned by the Department of Family and Community Services and is directed by the Melbourne Institute. This study uses data from the first wave of the survey, collated from interviews conducted with some 14,000 individuals living in almost 7,700 households over the second half of 2001. The survey contains a wealth of possible explanatory variables, covering four broad areas: economic wellbeing, labour market dynamics, family dynamics, and subjective wellbeing.
2.1 Constructing the Housing Leverage Variable
Housing leverage is typically expressed as a loan-to-valuation (LTV) ratio, in contrast to the debt-equity ratios commonly used in analysis of corporate finance. We can construct LTV ratios for homeowners' principal residence using information from the household questionnaire in Wave 1 of HILDA. Homeowners were asked to estimate the current value of their home, and to report the amount they currently owed on loans taken out against that home, including institutional mortgages, loans from family, friends and other members of the community, and home equity loans. To calculate the LTV ratio, we total the outstanding amounts of all borrowings against the principal residence and divide it by the estimate of the home's value. Households who rented, or who occupied their home rent-free but did not own it, were not asked these questions. Information on other properties such as investment properties or holiday homes was not included, so our study relates specifically to owner-occupiers' principal residences.
The use of subjective valuations raises the question of their accuracy. Goodman and Ittner (1993), using US survey data, find that there is a small positive bias of about 6 per cent in homeowners' estimates, but that the mean absolute error of estimates tends to be larger at about 15 per cent. This may be due to rounding errors: 42 per cent of households reporting estimated home values in HILDA reported a figure that was a multiple of $50,000. We believe our analysis is unlikely to be significantly biased by homeowners' subjectivity. If the bias in their estimates is small and, as Goodman and Ittner find, unrelated to owners' characteristics, then our point estimates will not be significantly biased even if these rounding errors make them less precise. In any case, households' behaviour presumably depends on their perceptions of their leverage rather than realised leverage, especially if they are not intending to sell their homes in the near future.
2.2 Missing Data and Income Imputation[1]
Compared with similar international household surveys, HILDA does not suffer greatly from problems of missing data (Watson and Wooden 2003). For example, only 4 per cent of households with mortgages fail to report the value of their loans, while the value of the principal residence is missing for only 6 per cent of owning households; these households are excluded from the results below. However, there is a relatively high incidence of missing data for income-related questions. We can separate the most common reasons for non-response into ‘item non-response’ and ‘incomplete households’. Item non-response occurs when a member of a selected household agrees to be interviewed, but then either refuses, or is unable, to answer some of the questions asked. This is the main source of missing data, accounting for 64 per cent of the missing household income information. Most of the missing income data is due to item non-response for income sourced from business (missing 23.5 per cent of people with business income) and investments (missing 8.1 per cent of recipients of this kind of income). Wages and salaries (missing 7.2 per cent of wage earners) and government benefits and pensions (missing 1.4 per cent of benefit recipients) have lower incidences of missing data.
The other major source of missing data is the 810 incomplete households, accounting for 10.5 per cent of the household sample and 36 per cent of the missing household income information; these are households in which not all eligible adult members agreed, or were able, to be interviewed. The HILDA dataset as distributed does not include an entry for household income if any of its eligible members were not interviewed, or did not report complete income information; in all, 29 per cent of households have a missing value for household income, which is clearly an unacceptable data loss.
In such circumstances we have two choices. We can drop the 29 per cent of households for which income data is missing from the sample, or impute the income of the individuals with missing data. Our choice to impute income for missing individuals is shaped by two factors. First, because income non-response is not random or uncorrelated with the variable(s) of interest, the missing cases cannot be safely dropped from the sample (Watson and Wooden 2003). For example, men, individuals outside the labour force, and people with large amounts of leisure time (and generally have low incomes) were more likely to offer complete income information than other individuals. Second, we have a large cross-section of information from the HILDA Survey that presumably permits us to do a reasonable job of imputing income where the information is missing.
2.2.1 Imputation methodology
Following the recommendations of the HILDA Survey team and methods adopted in the British Household Panel Survey (BHPS), we impute income using the predictive mean matching method (Little 1988; ISER 2002; Watson and Wooden 2003). This is a stochastic imputation technique that has the advantage of maintaining the underlying distribution of the data by allowing the imputation of error around the mean. Appendix A outlines the method in detail and shows the regression results for the three models.
The nature of the missing data leaves us with the need to impute income for three separate types of missing cases:
- Individuals that did not complete a person questionnaire and therefore did not report any income information (Type I) (n = 1158).
- Individuals that completed a person questionnaire but did not provide information on wage income (Type II) (n = 673).
- Individuals that completed a person questionnaire but did not provide information on non-wage income (Type III) (n = 1621).
Three separate models are estimated to impute income for each type of missing case. For Type I respondents we have information on the characteristics of their household (e.g., value of the dwelling, geographic location, the number of bedrooms) and a limited range of personal information from the household questionnaire. We also have personal information collected about other respondents in the household. These ‘family variables’ include the income, labour force status and occupation of other household members. Both the household and family variables are likely to be correlated with both personal and household income and hence act as useful explanatory variables in the model. We impute total gross financial year income for these individuals. For Types II and III respondents we also have additional personal information obtained from items that they did complete – labour force status, age, gender, English-speaking background – including information about the sources of their income. This allows us to predict wage and non-wage income, and add to it the income that individuals report from other sources. For example, for Type III individuals we add their imputed non-wage income to any actual reported wage and salary income.
2.2.2 Imputation results
In the regression model for Type I households our model explains nearly 32 per cent of the variation in total gross household income. The root mean square error (RMSE) is about $26,000. In the regression model for Type II households our model explains about 46 per cent of the variation in individuals' wage and salary income and the RMSE is nearly $19,000. In the regression model for Type III households our model explains nearly 21 per cent of the variation in individuals' non-wage income and the RMSE is about $20,500. Although these errors are quite large, we regard the imputation as being relatively successful, not least because it allows us to use reported income from other income sources and household members that would otherwise be lost.
Our income imputation strategy allowed us to recover household income estimates for all but 201 households (about 3 per cent of the sample), ensuring that any bias introduced by dropping missing observations from the sample is minimised. However, because our imputed household income estimates are likely to diverge from the true income that households did not report, we also construct a dummy variable for those households with imputed household income. This dummy was not significant in any of our three equations, implying that inclusion of households with imputed income did not significantly distort our results.
2.3 User Cost of Housing
The model outlined in Section 4 includes a model of households' tenure decisions. These depend on the utility they gain from owning rather than renting, and the relative costs of each tenure type. The relative cost of owning compared to renting is calculated by multiplying housing i's user cost of housing, uim, by the price-rent ratio in the relevant geographical area m. User cost captures the net per-unit cost of owning for owner-occupiers. We calculated it similarly to Bourassa (1995) as Equation (1), so as to take account of the details of Australia's tax system – specifically, that mortgage interest payments are not deductible.
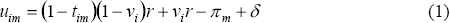
As is standard in the literature, per-unit user costs include the rate of depreciation δ, and the interest repayments on any mortgage, which in turn depend on interest rates r. Because interest payments are not deductible, this cost also depends on the mean expected leverage for household i's age group, vi. As in Bourassa (1995), this depends on the household's age and its permanent income, as estimated using its observable characteristics. The use of a group mean, not actual leverage, minimises any endogeneity concerns. There are also tax benefits to owner-occupation because the flow of housing services (imputed rent) is not taxed but actual rent is paid from post-tax income. Therefore there are tax and income costs to moving from owning to renting, as shown in the first term in Equation (1).[2] Owner-occupiers also accrue the benefit of expected capital gains on their home, πm, which are calculated here using past housing price inflation in market m. Bourassa (1994, 1995) contains more detail on the calculation of the components.
Footnotes
This section and Appendix A report work by Gianni La Cava and Jeremy Lawson. [1]
The income cost per unit of housing from moving from owning to renting is (1−vi)r. tim is the ratio of the change in tax payable to the change in income in moving from owning to renting, where the difference between the payable taxes in the tenure states are calculated using the household's permanent income. Thus,(1−tim)(1−vi)r is the per unit income and tax cost of moving from owning to renting. [2]