RDP 2008-02: Combining Multivariate Density Forecasts Using Predictive Criteria 3. Combining the Model Forecasts
May 2008
While each model included in the suite is estimated using different time series, the three core variables of interest – GDP growth, trimmed mean underlying inflation and the cash rate – are included in the data series for all three. To simplify notation, these three variables are collected in the vector zt = (Δgdpt πi it)′. It is each model's forecasting performance of the joint density p(zt+h|Ωt), where Ωt represents information available at time t, that will be used to combine the models. To simplify notation in what follows we leave out Ωt and use pt(zt+h) to denote an h step-ahead conditional predictive density but the dependence on the information set available at time t should be remembered.
The three models and how they map into the observable variables that we are interested in can be represented by a state space system:


where (6) is the state transition equation and (7) is the measurement equation. The subscript k is used to index the models and yk,t is the vector of model k's variables at time t. The matrices Ak and Ck will depend on the functional forms of the models and the estimated model-specific posterior parameter distributions while the matrix Dk maps each model's variables into the vector of interest zt. In the case of the BVAR and FAVAR models, where all variables in yk,t are observable, Dk is simply a selector matrix that picks out the variables included in zt.
3.1 Constructing Density Forecasts
The approach to constructing pt(zk,t+h)
is similar for each model. Multiple draws are taken from each model's
posterior parameter distribution and for each draw j, a potential
multivariate realisation 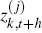 is constructed by iterating Equations (6)
and (7) forward up to horizon h. At each iteration, a vector of shocks
is constructed by iterating Equations (6)
and (7) forward up to horizon h. At each iteration, a vector of shocks
 is drawn from a mean zero normal distribution where the variance is itself a draw
from the relevant model's parameter distribution (that is,
is drawn from a mean zero normal distribution where the variance is itself a draw
from the relevant model's parameter distribution (that is, 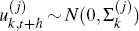 ). Repeating this procedure
j = 1,000 times at each forecast horizon allows us to build up a
complete picture of the forecast probability distribution. To complete the
density forecast, the potential realisations are ordered at each ‘slice’
in the forecast horizon. Each ordered set of realisations represents the h
step-ahead conditional density forecast for zk,t+h. Different
percentile bands are usually shaded when presenting the final forecast. Each
band represents a range in which we expect future realisations of zk,t
to fall in with a certain probability.
). Repeating this procedure
j = 1,000 times at each forecast horizon allows us to build up a
complete picture of the forecast probability distribution. To complete the
density forecast, the potential realisations are ordered at each ‘slice’
in the forecast horizon. Each ordered set of realisations represents the h
step-ahead conditional density forecast for zk,t+h. Different
percentile bands are usually shaded when presenting the final forecast. Each
band represents a range in which we expect future realisations of zk,t
to fall in with a certain probability.
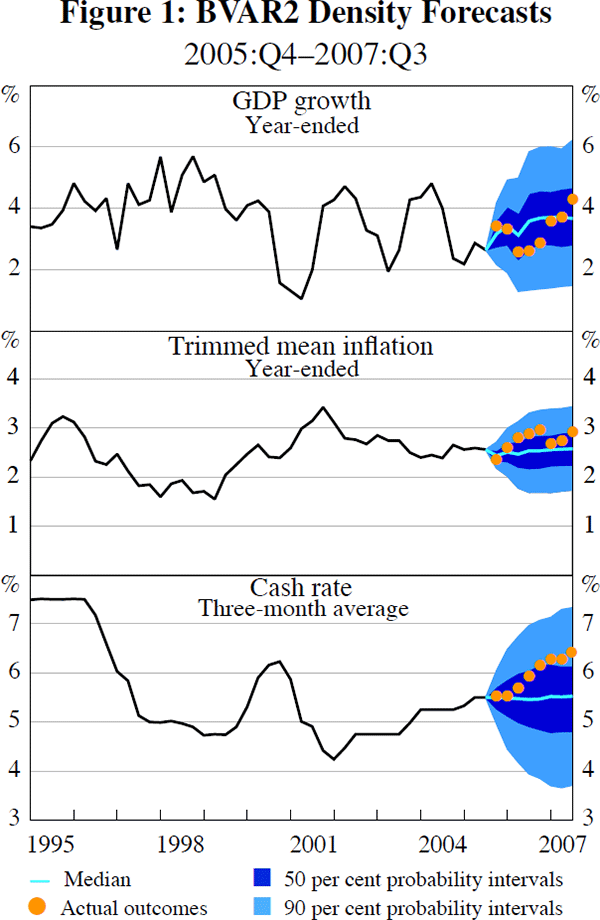
As an example, the density forecasts that would have been obtained using data up to 2005:Q3 with the BVAR2 model are presented in Figure 1. The median projection along with 50 and 90 per cent probability intervals are shown.
A combination density forecast, denoted 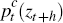 ,
can be constructed as a weighted linear
combination (or ‘linear opinion pool’) of the competing
model forecasts:
,
can be constructed as a weighted linear
combination (or ‘linear opinion pool’) of the competing
model forecasts:
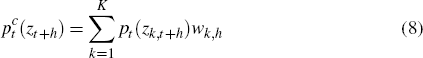
where wk,h represents the weight assigned to model k when forecasting at horizon h. The remainder of this section focuses on how to go about choosing these weights.
3.2 Equal and Posterior Probability Weights
The simplest and most straightforward weighting scheme is to put equal weight on all models in the suite. In this case, wk,h = 1/K at each forecast horizon. Apart from its simplicity, a priori this approach seems to have little going for it. For example, an over-parameterised model that forecasts poorly would still be assigned substantial weight.[2] But such a scheme has been found to perform well when combining point forecasts (see Timmermann 2006) and could also prove useful in a density combination context. One reason for this unexpected success may be that an equal-weighting scheme is robust to possible small-sample problems that may arise when choosing weights ‘optimally’.
An alternative and intuitive approach to combining models can be derived in a Bayesian framework. Each model's marginal likelihood, p(yk), could be used to generate posterior probability weights, a method known as Bayesian Model Averaging (see, for example, Raftery, Madigan and Hoeting 1997). That is,
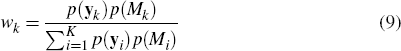
where p(Mk) represents any prior beliefs about model k being the true model.
This method is attractive as models that appear to describe the observed data better are assigned a higher weight. But a potential problem with using an in-sample measure to generate model weights is that too much weight may be placed on over-parameterised models with good in-sample fit even if they perform poorly when forecasting.[3]
A further issue is that the marginal likelihood reflects the entire fit of a model. The weights from Equation (9) will depend upon each model's description of all the variables making up yk, but yk differs between models.
Another approach that can be used to help control for in-sample over-fitting, and to focus on the key variables of interest, is an out-of-sample weighting scheme based on predictive likelihoods, as in Andersson and Karlsson (2007) and Eklund and Karlsson (2007).
3.3 Predictive-likelihood Weights
A weighting scheme based on predictive likelihoods requires the available data to be split into two samples. A ‘training’ sample is used to estimate the parameters of each model, and the remaining ‘hold-out’ sample is used to evaluate each model's out-of-sample forecasting performance. Asymptotically, that is, with an infinitely long hold-out sample, predictive likelihoods would tend to put all the weight on the best model. In practice, however, there is a trade-off between the length of training and hold-out samples. With a short training sample, a model's parameters will be imprecisely estimated. But lengthening the training sample necessarily shortens the hold-out sample, which makes the evaluation of the predictive criteria less precise. Therefore, in small samples, a poor model may still be assigned substantial weight. Worse still, if there are several poor models, their combined weight can be large.
It should be noted that the predictive likelihood is not an absolute measure of forecasting performance, but rather, it is a measure of forecasting accuracy relative to the variance implied by the model (see Andersson and Karlsson 2007 and Eklund and Karlsson 2007). This makes the predictive likelihood appealing when evaluating density forecasts from different models, although the ranking of models could be quite different to that obtained according to RMSEs based on point forecasts, for example.
As in Andersson and Karlsson (2007), we calculate a series of small hold-out sample predictive likelihoods (PL), as shown in Equation (10). This involves a recursive forecasting scheme where the training sample of initial size l is expanded throughout the forecasting exercise.[4] We also restrict our attention to each model's predictive performance of the subset of variables zk,t as set out in Equation (7).
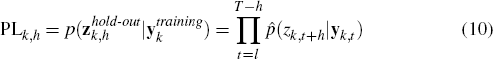
In Equation (10), 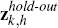 denotes the (T − h − l) hold-out observations
used to evaluate model k at horizon h,
denotes the (T − h − l) hold-out observations
used to evaluate model k at horizon h, 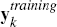 represents the (expanding)
training sample and yk,t = (yk1
… yk,t)′ represents each individual training
sample relevant to iteration t in the recursive forecasting
exercise.[5]
represents the (expanding)
training sample and yk,t = (yk1
… yk,t)′ represents each individual training
sample relevant to iteration t in the recursive forecasting
exercise.[5]
The predictive-likelihood weights can be calculated by replacing the marginal likelihood in Equation (9) with the predictive likelihood of Equation (10) as follows:
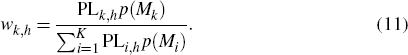
In the analysis below, we assign an equal prior probability to each model being the true model, that is, p(Mk) = 1/K.[6]
Footnotes
Also, models that were quite similar would tend to be ‘over-represented.’ [2]
While it is possible to view the marginal likelihood as an out-of-sample measure, this interpretation relies on the predictive content of the prior (see, for example, Adolfson, Lindé and Villani 2005 and Eklund and Karlsson 2007). This will only be true for the DSGE model in our suite of models and, in that case, the marginal likelihood is likely to be sensitive to the choice of prior. For both the BVAR and FAVAR models, where either diffuse or relatively uninformative priors are imposed, the marginal likelihood reflects an in-sample measure of fit. [3]
Theoretically, either a fixed- or rolling-window forecasting scheme would be preferred to accommodate the idea that the hold-out sample should tend towards infinity. With dynamic models, however, a fixed estimation window is not suitable as forecasts would essentially lack information available at the time of forecasting. The rolling-window scheme is also not practical when faced with a short sample of data. We therefore prefer the recursive approach. [4]
More details on how the predictive likelihood (10) was calculated are provided in Appendix A. [5]
We also generated weights numerically following Hall and Mitchell (2007) when choosing the set of weights that minimise the Kullback-Leibler divergence between the combined density forecast and the true but unknown density. When considering a small number of models, the weights obtained were similar to those of the predictive-likelihood approach, but this Kullback-Leibler information criterion weighting scheme, which involves a numerical search for the optimal set of weights, becomes impractical when considering a larger model space. [6]