RDP 2010-04: Employment Composition: A Study of Australian Employment Growth, 2002–2006 5. Unemployment, Marginal Attachment and Not in the Labour Force
June 2010
- Download the Paper 309KB
5.1 Multinomial Logit Model – Methodology
The binomial logit model above treats all people not employed as similar. However, ‘not employed’ consists of three separate groups with potentially quite different characteristics: the unemployed, the marginally attached and those not in the labour force. To look at how the mix of individuals in each of these pools has changed over time we repeat the analysis by splitting the not-employed into the three groups and comparing each to the employed group using a multinomial logit model.
We treat the marginally attached (individuals wanting work but either unavailable in the reference week or with no search activity) as being separate to the group of individuals who are not in the labour force (that is, not available and not searching for work) for several reasons: the average characteristics exhibited by the marginally attached can differ significantly from those not in the labour force; their transition rates into employment and unemployment are higher than for the group of those not in the labour force (Gray et al 2002); and they form a group twice as large as the unemployed pool.
We follow the same procedure as for the binomial logit in Section 4. We first estimate the multinomial logit model to determine which characteristics are associated with each of the not-employed states in 2002, in 2006 and on average over the two years (using pooled data). We then run a formal test for a change in the distribution over time by interacting a 2006 dummy variable with each characteristic. If the dummy variables are jointly different from 1, then the relationships between the not-employed state in question and individual characteristics will have changed between 2002 and 2006.
For each alternative labour force state, the multinomial logit estimates the probability that a person with a given set of characteristics is a member of that state. For example, for unemployment this is:
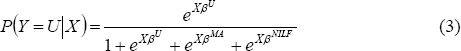
X is the same vector of dummy variables indicating personal characteristics
as used in Section 4 and βY
is now the vector of coefficients associated with labour force status Y
= U, MA or NILF – for unemployed, marginally
attached or not in the labour force, respectively – rather than employment,
E. Employment is now set as the base case, so that 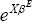 is normalised to equal 1.
Doing this allows us to calculate the relative probability of being in one
of three labour force states (Y = U, MA or NILF)
rather than in employment for a given set of characteristics, called the relative risk
(of that particular state). For unemployment this would be:
is normalised to equal 1.
Doing this allows us to calculate the relative probability of being in one
of three labour force states (Y = U, MA or NILF)
rather than in employment for a given set of characteristics, called the relative risk
(of that particular state). For unemployment this would be:

Using this information we can then calculate a relative risk ratio (RRR) of unemployment for characteristic xi. This measures the relative risk of being unemployed for a person who exhibits that particular characteristic (but in all other ways has the set of base characteristics) compared to the relative risk of being unemployed for a person who has the full set of base characteristics:
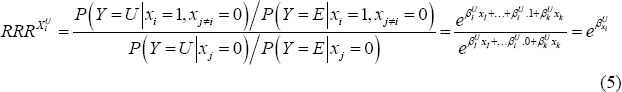
With employment as the base case, the RRR of unemployment tells us how each characteristic affects the probability of being in unemployment rather than in employment. For example, if the relative risk ratio associated with poor health in the marginal attachment regression is 2 then an individual with poor health is twice as likely to be marginally attached than employed compared to someone who is healthy (which is the base for this characteristic). There is a separate RRR for each characteristic for each of the labour force states, so a characteristic may have a high RRR with respect to unemployment but a low RRR with respect to not being in the labour force. This feature of the multinomial logit allows us to gather a significant amount of information about how each characteristic is related to labour force status.
5.2 Comparing Characteristics across Not-employed States
In order to gauge how strongly each characteristic is associated with each not-employed state, we can directly compare the size of the RRR for the same characteristic across the unemployment, marginal attachment and not-in-the-labour-force regression results. This is possible because employment is used as the common base case. For example, the RRR of unemployment for those aged 56–65 years is not significant, whereas the RRR of not being in the labour force for those aged 56–65 years is 5.0 and significantly different from 1 (in the pooled regression). Together, these results indicate that along this dimension the not-in-the-labour-force group are very different to the employed group, whereas the unemployed are not very different. Looking across all the pooled results in Tables 2A–C, we find that the unemployed are the most similar to the employed – for most characteristics the RRR of unemployment is closest to 1 for the unemployment regression – while the not-in-the-labour-force group is the least similar to the employed group. The marginally attached are somewhere in between.
| Pooled | 2002 | 2006 | Diff(b) | |
|---|---|---|---|---|
| 2006 (vs 2002) | 0.9 | |||
| Age (vs 36–45 years) | ||||
| 18–25 years | 1.2 | 1.2 | 1.3 | |
| 26–35 years | 1.1 | 1.0 | 1.4 | |
| 46–55 years | 0.9 | 0.8 | 1.2 | |
| 56–65 years | 0.9 | 0.9 | 0.9 | |
| Birth country (vs Australia) | ||||
| English-speaking | 1.1 | 1.2 | 1.1 | |
| Non-English-speaking | 1.3* | 1.5** | 1.1 | |
| Education (vs university) | ||||
| Diploma or certificate | 1.4* | 1.6** | 1.2 | |
| High school | 0.9 | 1.0 | 0.9 | |
| Less than high school | 1.2 | 1.4 | 1.0 | |
| Occupation (vs professional) | ||||
| Associate professional | 1.0 | 1.0 | 0.9 | |
| Trade | 0.9 | 0.9 | 0.8 | |
| Production | 1.9*** | 1.9** | 2.0** | |
| Unskilled | 1.4* | 1.6* | 1.2 | |
| Father's occupation (vs professional) | ||||
| Associate professional | 0.9 | 1.0 | 0.8 | |
| Trade | 0.8 | 0.6** | 1.1 | * |
| Production | 0.8 | 0.7* | 1.0 | |
| Unskilled | 1.3 | 1.2 | 1.6* | |
| Mother's employment status (vs employed) | ||||
| Not employed | 1.0 | 0.9 | 1.0 | |
| Student status (vs not student) | ||||
| Enrolled full-time | 0.9 | 0.7* | 1.1 | |
| Finished studies 1–2 years ago | 0.7* | 0.6 | 0.7 | |
| Time in work in previous year (vs 100 per cent) | ||||
| 0 per cent | 109.9*** | 143.7*** | 89.0*** | |
| 1–25 per cent | 36.8*** | 36.9*** | 38.9*** | |
| 26–50 per cent | 22.4*** | 24.4*** | 21.7*** | |
| 51–75 per cent | 15.6*** | 16.9*** | 14.9*** | |
| 76–99 per cent | 10.2*** | 11.5*** | 8.4*** | |
| Time in work since school (vs more than 50 per cent) | ||||
| Less than 50 per cent | 1.4** | 1.2 | 1.6** | |
| Has health condition (vs healthy) | 1.3* | 1.4* | 1.2 | |
| Housing tenure (vs mortgagee) | ||||
| Outright owner | 1.0 | 0.9 | 1.2 | |
| Renter | 0.7* | 0.8 | 0.6 | |
| Family status (vs male couple with no child) | ||||
| Female | 0.8** | 0.9 | 0.6** | |
| Single with no child | 1.3* | 1.4 | 1.2 | |
| Couple, male, child 0–4 years | 0.8 | 0.9 | 0.7 | |
| Couple, male, child 5–24 years | 0.7 | 0.7 | 0.6 | |
| Couple, female, child 5–24 years | 0.8 | 0.7 | 0.9 | |
| Couple, female, child 0–4 years | 0.7 | 1.0 | 0.4** | |
| Single, child 0–14 years | 1.0 | 0.8 | 1.2 | |
| Has non-resident child | 0.8 | 0.8 | 0.9 | |
| Net wealth (vs top quintile) | ||||
| 1st quintile | 5.1*** | 4.6*** | 6.0*** | |
| 2nd quintile | 2.8*** | 2.6*** | 3.2*** | |
| 3rd quintile | 2.5*** | 2.5*** | 2.6*** | |
| 4th quintile | 2.0*** | 2.2*** | 1.8* | |
| Income less own labour income (vs top quintile) | ||||
| 1st quintile | 0.7 | 0.8 | 0.7 | |
| 2nd quintile | 0.8 | 0.8 | 0.8 | |
| 3rd quintile | 0.9 | 0.9 | 1.0 | |
| 4th quintile | 0.9 | 0.9 | 0.9 | |
| Debt-to-income ratio (vs above 3) | ||||
| 0 | 1.8*** | 1.6* | 1.9** | |
| 0–1 | 1.9*** | 1.6* | 2.3*** | |
| 1–3 | 1.3 | 1.2 | 1.5 | |
| Remoteness (vs capital city) | ||||
| Major city | 1.0 | 1.1 | 0.9 | |
| Rural | 1.0 | 0.9 | 1.3 | |
| State or Territory (vs NSW) | ||||
| Victoria | 1.0 | 1.0 | 0.9 | |
| Queensland | 0.9 | 1.1 | 0.7* | |
| South Australia | 0.7** | 1.0 | 0.4*** | * |
| Western Australia | 0.7* | 0.7 | 0.8 | |
| Tasmania | 0.8 | 1.6 | 0.3** | *** |
| Northern Territory | 0.3 | 0.2 | 0.4 | |
| ACT | 0.8 | 1.4 | 0.5 | |
| Imputed (vs not imputed)(c) | 0.7*** | 0.8** | 0.7** | |
| Wald test of set of 2006 dummies within U regression equal to zero (p-value) | 0.83 | |||
| Memo items: | ||||
| Number of observations | 17,606 | 8,952 | 8,654 | |
| Likelihood ratio test (p-value) | 0.00 | 0.00 | 0.00 | |
| Pseudo R2 | 0.53 | 0.54 | 0.54 | |
| Predictive power(d) | 87.6 | 86.8 | 89.0 | |
| Wald test of full set of 2006 dummies across all of U, MA and NILF regressions (p-value) | 0.13 | |||
| Notes: (a) Base case is indicated in brackets for each group of categorical variables. Standard errors calculated using White's robust variance estimator. *, ** and *** indicate significance at the 10, 5 and 1 per cent levels respectively. (b) Results from a regression of employment status on characteristic type and a set of dummies that interact characteristics with the year 2006. Null hypothesis is that the coefficient on the 2006 characteristic is equal to zero, that is, no difference in the relative probability of employment between 2006 and 2002 for that characteristic compared to the base case. (c) Some data cells, particularly regarding household wealth, are imputed for some individuals. This variable is included as a control variable. (d) Percentage of observations correctly predicted, where the rule is that the labour force status predicted for each individual is the category with the highest probability. |
||||
| Pooled | 2002 | 2006 | Diff(b) | |
|---|---|---|---|---|
| 2006 (vs 2002) | 1.1 | |||
| Age (vs 36–45 years) | ||||
| 18–25 years | 0.6*** | 0.6* | 0.6** | |
| 26–35 years | 1.0 | 0.9 | 1.2 | |
| 46–55 years | 1.9*** | 2.0*** | 1.9*** | |
| 56–65 years | 5.0*** | 5.7*** | 4.6*** | |
| Birth country (vs Australia) | ||||
| English-speaking | 0.9 | 1.0 | 0.9 | |
| Non-English-speaking | 1.4*** | 1.6*** | 1.2 | |
| Education (vs university) | ||||
| Diploma or certificate | 1.3** | 1.8*** | 1.0 | ** |
| High school | 1.2 | 1.5* | 1.0 | |
| Less than high school | 1.8*** | 2.6*** | 1.2 | *** |
| Occupation (vs professional) | ||||
| Associate professional | 1.2 | 1.1 | 1.3 | |
| Trade | 1.3 | 1.0 | 1.6* | |
| Production | 1.4* | 1.2 | 1.5 | |
| Unskilled | 1.1 | 1.2 | 1.0 | |
| Father's occupation (vs professional) | ||||
| Associate professional | 0.9 | 1.2 | 0.7* | ** |
| Trade | 0.8** | 0.7** | 0.9 | |
| Production | 0.9 | 0.8 | 0.9 | |
| Unskilled | 1.1 | 1.1 | 1.0 | |
| Mother's employment status (vs employed) | ||||
| Not employed | 1.0 | 0.9 | 1.0 | |
| Student status (vs not student) | ||||
| Enrolled full-time | 1.3 | 1.2 | 1.5* | |
| Finished studies 1–2 years ago | 0.6** | 0.7 | 0.6** | |
| Time in work in previous year (vs 100 per cent) | ||||
| 0 per cent | 584.3*** | 721.5*** | 554.6*** | |
| 1–25 per cent | 37.0*** | 50.3*** | 26.3*** | * |
| 26–50 per cent | 21.0*** | 28.7*** | 15.4*** | * |
| 51–75 per cent | 22.3*** | 27.3*** | 18.9*** | |
| 76–99 per cent | 15.3*** | 16.1*** | 14.1*** | |
| Time in work since school (vs more than 50 per cent) | ||||
| Less than 50 per cent | 1.3** | 1.2 | 1.5** | |
| Has health condition (vs healthy) | 2.5*** | 3.0*** | 2.2*** | |
| Housing tenure (vs mortgagee) | ||||
| Outright owner | 1.1 | 1.1 | 1.1 | |
| Renter | 0.7** | 0.9 | 0.7* | |
| Family status (vs male couple with no child) | ||||
| Female | 1.6*** | 2.0*** | 1.3* | * |
| Single with no child | 0.9 | 0.7* | 1.1 | * |
| Couple, male, child 0–4 years | 0.6* | 0.4** | 0.9 | |
| Couple, male, child 5–24 years | 0.7** | 0.6* | 0.8 | |
| Couple, female, child 5–24 years | 0.8 | 0.8 | 0.9 | |
| Couple, female, child 0–4 years | 5.6*** | 6.4*** | 5.8*** | |
| Single, child 0–14 years | 0.9 | 0.8 | 1.0 | |
| Has non-resident child | 0.6*** | 0.6** | 0.6** | |
| Net wealth (vs top quintile) | ||||
| 1st quintile | 1.1 | 1.0 | 1.2 | |
| 2nd quintile | 1.1 | 1.2 | 0.9 | |
| 3rd quintile | 1.2 | 1.3 | 1.2 | |
| 4th quintile | 1.1 | 1.3 | 0.9 | |
| Income less own labour income (vs top quintile) | ||||
| 1st quintile | 0.5*** | 0.8 | 0.4*** | ** |
| 2nd quintile | 0.8 | 0.9 | 0.8 | |
| 3rd quintile | 0.7** | 0.8 | 0.7* | |
| 4th quintile | 0.7** | 0.9 | 0.6** | |
| Debt-to-income ratio (vs above 3) | ||||
| 0 | 2.2*** | 2.3*** | 2.1*** | |
| 0–1 | 1.6*** | 1.8*** | 1.4* | |
| 1–3 | 1.1 | 1.2 | 1.1 | |
| Remoteness (vs capital city) | ||||
| Major city | 0.9 | 0.8 | 1.0 | |
| Rural | 1.0 | 0.8 | 1.3 | ** |
| State or Territory (vs NSW) | ||||
| Victoria | 1.2 | 1.0 | 1.3* | |
| Queensland | 1.3** | 1.2 | 1.4** | |
| South Australia | 1.1 | 1.2 | 1.1 | |
| Western Australia | 1.2 | 1.2 | 1.3 | |
| Tasmania | 1.5* | 2.1** | 1.1 | |
| Northern Territory | 0.4 | 0.1*** | 1.5 | ** |
| ACT | 1.0 | 1.3 | 0.8 | |
| Imputed (vs not imputed)(c) | 0.6*** | 0.7*** | 0.6*** | |
| Wald test of set of 2006 dummies within NILF regression equal to zero (p-value) | 0.05 | |||
| Memo items: | ||||
| Number of observations | 17,606 | 8,952 | 8,654 | |
| Likelihood ratio test (p-value) | 0.00 | 0.00 | 0.00 | |
| Pseudo R2 | 0.53 | 0.54 | 0.54 | |
| Predictive power(d) | 87.6 | 86.8 | 89.0 | |
| Wald test of full set of 2006 dummies across all of U, MA and NILF regressions (p-value) | 0.13 | |||
| Notes: (a) Base case is indicated in brackets for each group of categorical variables. Standard errors calculated using White's robust variance estimator. *, ** and *** indicate significance at the 10, 5 and 1 per cent levels respectively. (b) Results from a regression of employment status on characteristic type and a set of dummies that interact characteristics with the year 2006. Null hypothesis is that the coefficient on the 2006 characteristic is equal to zero, that is, no difference in the relative probability of employment between 2006 and 2002 for that characteristic compared to the base case. (c) Some data cells, particularly regarding household wealth, are imputed for some individuals. This variable is included as a control variable. (d) Percentage of observations correctly predicted, where the rule is that the labour force status predicted for each individual is the category with the highest probability. |
||||
| Pooled | 2002 | 2006 | Diff(b) | |
|---|---|---|---|---|
| 2006 (vs 2002) | 0.9* | |||
| Age (vs 36–45 years) | ||||
| 18–25 years | 0.7** | 0.6* | 0.8 | |
| 26–35 years | 1.1 | 0.8 | 1.4* | * |
| 46–55 years | 1.3** | 1.4* | 1.2 | |
| 56–65 years | 1.5** | 1.7** | 1.3 | |
| Birth country (vs Australia) | ||||
| English-speaking | 1.1 | 1.1 | 1.0 | |
| Non-English-speaking | 1.4** | 1.3 | 1.5** | |
| Education (vs university) | ||||
| Diploma or certificate | 1.1 | 1.3 | 0.9 | |
| High school | 1.1 | 1.2 | 1.1 | |
| Less than high school | 1.5** | 1.6** | 1.4 | |
| Occupation (vs professional) | ||||
| Associate professional | 1.3* | 1.3 | 1.3 | |
| Trade | 1.2 | 1.1 | 1.1 | |
| Production | 1.6** | 1.3 | 1.9** | |
| Unskilled | 1.3 | 1.4 | 1.2 | |
| Father's occupation (vs professional) | ||||
| Associate professional | 1.0 | 1.2 | 0.8 | |
| Trade | 0.8 | 0.8 | 0.9 | |
| Production | 0.8** | 0.6** | 0.9 | |
| Unskilled | 1.2 | 1.5* | 0.9 | |
| Mother not employed (vs employed) | ||||
| Not employed | 0.9 | 0.8* | 1.0 | |
| Student status (vs not student) | ||||
| Enrolled full-time | 1.4** | 1.5* | 1.4 | |
| Finished studies 1–2 years ago | 0.9 | 0.8 | 1.0 | |
| Time in work in previous year (vs 100 per cent) | ||||
| 0 per cent | 353.0*** | 466.3*** | 315.5*** | |
| 1–25 per cent | 33.9*** | 43.0*** | 29.0*** | |
| 26–50 per cent | 26.7*** | 36.2*** | 20.9*** | |
| 51–75 per cent | 17.9*** | 25.5*** | 13.4*** | * |
| 76–99 per cent | 8.8*** | 8.3*** | 9.2*** | |
| Time in work since school (vs more t han 50 per cent) | ||||
| Less than 50 per cent | 1.1 | 1.1 | 1.1 | |
| Has health condition (vs healthy) | 1.9*** | 2.2*** | 1.6*** | |
| Housing tenure (vs mortgagee) | ||||
| Outright owner | 1.3 | 1.4* | 1.0 | |
| Renter | 0.9 | 1.0 | 0.8 | |
| Family status (vs male in couple with no child) | ||||
| Female | 1.0 | 1.0 | 1.1 | |
| Single with no child | 1.2 | 1.0 | 1.5** | |
| Couple, male, child 0–4 years | 0.8 | 0.8 | 0.9 | |
| Couple, male, child 5–24 years | 0.7 | 0.7 | 0.9 | |
| Couple, female, child 5–24 years | 1.3 | 1.5 | 1.1 | |
| Couple, female, child 0–4 years | 4.1*** | 6.2*** | 2.7*** | ** |
| Single, child 0–14 years | 2.0*** | 2.0** | 2.0** | |
| Has non-resident child | 0.7* | 0.7 | 0.8 | |
| Net wealth (vs top quintile) | ||||
| 1st quintile | 1.8*** | 1.5 | 2.2** | |
| 2nd quintile | 1.4* | 1.1 | 1.7* | |
| 3rd quintile | 1.4** | 1.3 | 1.5* | |
| 4th quintile | 1.2 | 1.2 | 1.2 | |
| Income less own labour income (vs top quintile) | ||||
| 1st quintile | 0.5*** | 0.8 | 0.4*** | * |
| 2nd quintile | 0.8 | 1.1 | 0.6** | ** |
| 3rd quintile | 0.7** | 0.7 | 0.7* | |
| 4th quintile | 0.8* | 1.0 | 0.6** | |
| Debt-to-income ratio (vs above 3) | ||||
| 0 | 1.6*** | 2.1*** | 1.4 | |
| 0–1 | 1.6*** | 2.2*** | 1.3 | * |
| 1–3 | 1.4** | 2.1*** | 1.0 | ** |
| Remoteness (vs capital city) | ||||
| Major city | 1.0 | 1.1 | 0.9 | |
| Rural | 1.1 | 1.2 | 1.1 | |
| State or Territory (vs NSW) | ||||
| Victoria | 1.1 | 1.0 | 1.2 | |
| Queensland | 1.1 | 1.1 | 1.1 | |
| South Australia | 1.0 | 1.0 | 1.1 | |
| Western Australia | 0.8 | 1.0 | 0.6* | |
| Tasmania | 1.6** | 2.1** | 1.4 | |
| Northern Territory | 0.5 | 0.2** | 0.7 | |
| ACT | 0.6 | 0.7 | 0.6 | |
| Imputed (vs not imputed)(c) | 0.7*** | 0.7** | 0.7*** | |
| Wald test of set of 2006 dummies within MA regression equal to zero (p-value) | 0.11 | |||
| Memo items: | ||||
| Number of observations | 17,606 | 8,952 | 8,654 | |
| Likelihood ratio test (p-value) | 0.00 | 0.00 | 0.00 | |
| Pseudo R2 | 0.53 | 0.54 | 0.54 | |
| Predictive power(d) | 87.6 | 86.8 | 89.0 | |
| Wald test of full set of 2006 dummies across all of U, MA and NILF regressions (p-value) | 0.13 | |||
| Notes: (a) Base case is indicated in brackets for each group of categorical variables. Standard errors calculated using White's robust variance estimator. *, ** and *** indicate significance at the 10, 5 and 1 per cent levels respectively. (b) Results from a regression of employment status on characteristic type and a set of dummies that interact characteristics with the year 2006. Null hypothesis is that the coefficient on the 2006 characteristic is equal to zero, that is, no difference in the relative probability of employment between 2006 and 2002 for that characteristic compared to the base case. (c) Some data cells, particularly regarding household wealth, are imputed for some individuals. This variable is included as a control variable. (d) Percentage of observations correctly predicted, where the rule is that the labour force status predicted for each individual is the category with the highest probability. |
||||
The results also confirm that the characteristics associated with each labour force status are different from each other, in ways that we might generally expect (Tables 2A–C). Almost by definition, the unemployed will have a relatively high propensity to supply labour but may face a relatively low demand for the skills or experience they have to offer. Consistent with this, our results show that unemployment tends to be associated with males, unskilled or production workers and those with a diploma-level of education (Table 2A). Also, unemployment is strongly related to low net wealth and a lack of recent labour market experience.[11]
In contrast, not being in the labour force is associated with characteristics that generally indicate a lower propensity to supply labour: older people; women (particularly with young children); high household income and low debt levels; and a lower level of education. Not being in the labour force appears unrelated to net wealth (Table 2B). The finding that women are more likely to not be in the labour force, even if they do not have dependent children, may reflect the tendency for women to retire earlier than men. The fact that those people with less than high school education are more likely to not be in the labour force is consistent with the idea that the decision to increase education is closely related to an individual's willingness to be in the labour force.
Those in marginal attachment have features in common with both the unemployed and not-in-the-labour-force pools. In particular, marginal attachment tends to be associated with older workers, women with young children, single parents, those people with less than a high school education, migrants from non-English-speaking countries, higher levels of household income and low debt-to-income ratios (Table 2C). Like unemployment, it is negatively related to net wealth.
From this, three key groups appear prominent in the group of marginally attached individuals: those aged over 45 years; single parents; and partnered women with children. Their status suggests that for some reason these groups typically do not undertake much job search or find it difficult to begin work immediately, yet report that they would like to work. Understanding the behaviour of these groups requires a better knowledge of job search activity and the transition from non-work to work.
5.3 Comparing 2002 and 2006
A key point of this paper is to see how the association between characteristics and labour market status may have changed after a period of strong employment growth. Unlike for the binomial regression, we find that there has been a statistically significant change between 2002 and 2006; a Wald test of the significance of the full set of 2006 interactive dummies for the not-in-the-labour-force regression has a p-value of 5 per cent (while the p-value of the test for marginal attachment regression is 11 per cent). Further, for both the marginal attachment and not-in-the-labour-force regressions, the 2006 coefficient estimates for several groups of characteristics are statistically different to the 2002 estimates (see Appendix Table B2).
These results have two key implications. First, much of the increase in the rate of employment over this period was generated by higher participation, suggesting a significant role for changes in labour supply. Second, the pool of those who are unemployed does not appear to have become more concentrated in characteristics associated with low employment rates.
5.3.1 Marginal attachment and not in the labour force
The joint test of the interactive dummies indicates some change in the characteristics of the not-in-the-labour-force and marginally attached groups. More specifically, we find that for both of these groups:
- the RRR decreased for older people, reflecting an increase in participation by these cohorts between 2002 and 2006;
- the RRR decreased for mothers in a couple with young children;
- the RRR decreased for those who had not been fully employed in the previous year (that is, less than 100 per cent of their available time working); and
- the RRRs decreased for low income and poor health, as well as unskilled occupations and less-than-high-school education, consistent with an increase in demand for, and supply of, such workers during an extended upswing in economic activity.
It is worth noting that these first two points are consistent with the documented delay in retirement and increased use of childcare (as indicated by ABS data). It is likely that policy and attitudinal changes have influenced these decisions, as a four-year period is probably too short for cohort effects to be important.
Based on HILDA data, the marginal attachment rate fell much more than the not-in-the-labour-force rate over the period 2002 to 2006. This has implications for measuring labour supply. Currently, the marginally attached are contained within the not-in-the-labour-force group in the standard LFS measure of labour force participation. However, as much of the extra employment has been due to a fall in marginal attachment, a broader (and potentially more relevant) measure of participation may include the marginally attached in the labour force. This is also consistent with the finding that the marginally attached have many characteristics in common with the unemployed in terms of their prospects of employment. Using LFS data for those aged 15–69 years, this alternative definition of the labour force would suggest a slower rate of growth in labour supply from 2002 to 2006 (from 78.3 per cent to 79.3 per cent) than the standard definition (from 72.2 per cent to 74.2 per cent).[12]
5.3.2 Unemployment
The relationship between personal characteristics and unemployment appears to have changed by less between 2002 and 2006 than for the other two not-employed categories; the Wald test reports that the set of interactive dummies are not jointly significantly different from 1 and very few interactive dummies are individually significant. This suggests that on average, the characteristics of the unemployed pool have not changed substantially between 2002 and 2006. As is the case for the other labour force states, the point estimates suggest that characteristics associated with the lowest employment rates in 2002 (such as being from a non-English-speaking country, having less than university-level education, being unskilled, having little recent work experience, or being in poor health) were less likely to be associated with unemployment in 2006.
5.4 Comment
Our results indicate that as employment expanded between 2002 and 2006 lower-skilled workers and groups which had lower participation rates were drawn into employment at slightly higher rates than groups with high employment rates in 2002. In general, this is consistent with Okun's theory that during a period of expansion, workers in the labour market trade up and vacancies are filled by less-skilled workers. It is also consistent with the notion that structural changes have occurred in the labour market to support participation by groups which typically have low participation rates, such as mothers with young children and older workers.
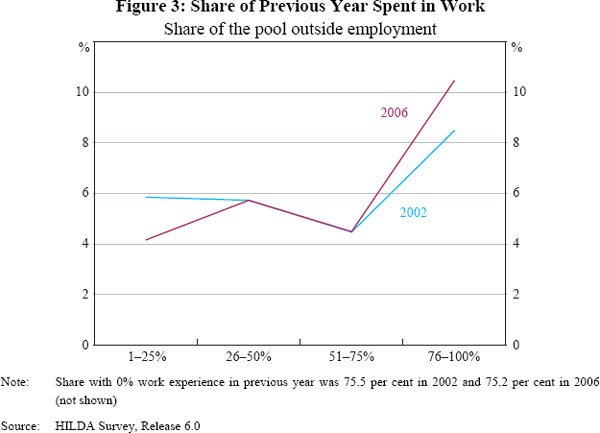
Further, there was a notable rise in the level of experience of the not-employed pool; from 2002 and 2006, the share of people with very low previous work experience fell, while the share of people who had worked for over 75 per cent of the previous year rose (Figure 3). This reflects the fact that there is considerable churn in the labour market as individuals move between jobs and in and out of employment.[13] As the employment rate rose over this period, the duration of employment and the probability of finding employment also increased, raising the average level of recent work experience of the whole population. This suggests that at high levels of employment, the average level of experience of the population is higher, somewhat mitigating against a shortage of suitable labour.
Footnotes
An insignificant coefficient on youth in the unemployment regression is somewhat surprising given the relatively high rate of unemployment for this category. This result is partly due to the exclusion of those who have never worked from our sample, as well as the fact that net wealth is highly correlated with age. [11]
Data on the marginally attached for 2002 and 2006 are only available for the age group 15–69 years and not for the standard labour force sample that covers those aged 15 years and above. See ABS 2007. [12]
Monthly LFS data from 2000–2005 indicate that around 4 per cent of employees are not employed in the next month, while just over 20 per cent of the unemployed and 10 per cent of NILF are employed in the next month. In the annual HILDA sample, around 8 per cent of the employed are not employed when interviewed the following year, while around 50 per cent of the unemployed and 20 per cent of those not in the labour force were employed when interviewed in the following year (for the period 2001/02 to 2004/05) (Carroll and Poehl 2007). [13]