RDP 9111: Monthly Movements in the Australian Dollar and Real Short-Term Interest Differentials: An Application of the Kalman Filter Appendix 2: Our Estimation Procedure – A Flow Chart[45]
November 1991
- Download the Paper 488KB
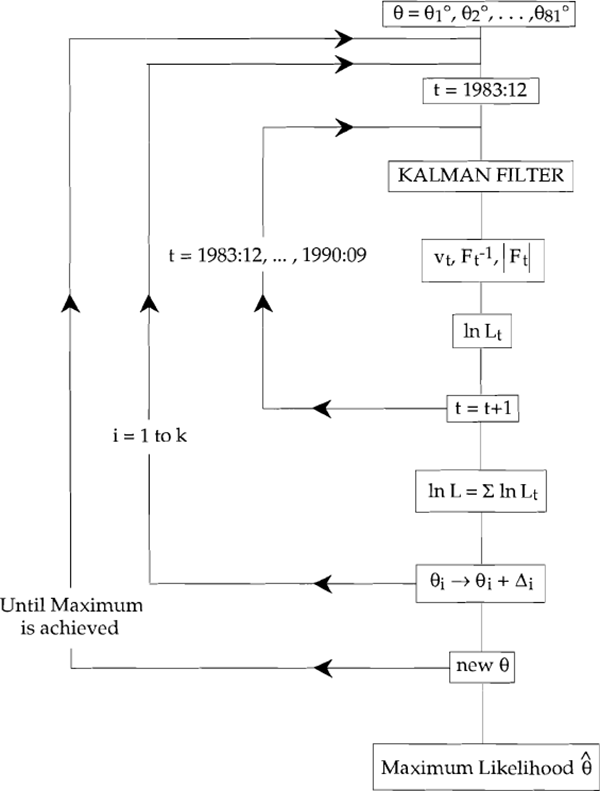
Our estimation process is activated with an initial choice of θ. The Kalman filter recursion begins at our first data observation, December 1983, and uses this first θ to compute the Kalman predictors via:
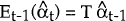
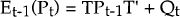
where:
-
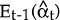 is the
minimum MS linear estimator of the state vector, αt;
is the
minimum MS linear estimator of the state vector, αt;
- T is the matrix of coefficients on αt−1 in the transition equation of our state space model;
-
Pt is the error covariance matrix of
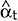 ;
;
- Qt is the covariance matrix for ηt, the vector of disturbance terms in the transition equation.
The following “updating” equations are then applied:
-
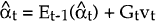
where:
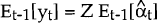 is known as the Kalman Gain.
is known as the Kalman Gain.
This “correction” term modifies the estimator,
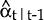 ;
and
;
and 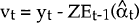 .
.
-
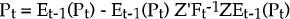
-
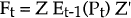
where:
- Z is the vector of coefficients on αt in the measurement equation;
-
Ft is the estimated covariance matrix of the one-step-ahead prediction errors
made in estimating the vector of observable explanatory variables and denoted vt,
such that:
vt = yt − Et−1(yt).
Therefore, three different errors play a role in the Kalman Filter:
-
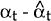 , the
error in the optimal predictor. This error has covariance matrix Pt.
, the
error in the optimal predictor. This error has covariance matrix Pt.
-
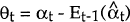 , where
, where
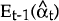 is
the optimal predictor of αt given observations up to t−1. Et−1(Pt)
is its covariance matrix.
is
the optimal predictor of αt given observations up to t−1. Et−1(Pt)
is its covariance matrix.
-
vt = yt − Et−1(yt), where Et−1(yt) is the one-step-ahead prediction of the observation yt:
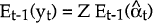
Ft is the covariance matrix of vt.
Given 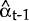 and
Pt−1 the workings of the filter can be described by a simple diagram:
and
Pt−1 the workings of the filter can be described by a simple diagram:
| Predicting | Updating |
|---|---|
| Pt−1 → Et−1(Pt) | → Ft → Pt |
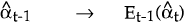 |
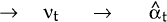 |
The normally distributed prediction errors and their variances generated in this way by the filter are used to calculate the likelihood function. This process is continued for each period in our data set.
The likelihood is then evaluated from the first time period, December 1983. Our search routine, the BHHH algorithm, finds that value of q which maximises log L.
Footnote
This appendix benefits from discussion with Professor Howard Doran of the University of New England, and this diagrammatic representation of the Kalman Filter is an adaptation of that found in Doran (1990). [45]