RDP 8706: Numerical Solution of Rational Expectations Models with and Without Strategic Behaviour 4. A Numerical Algorithm that Allows for Strategic Behaviour
August 1987
- Download the Paper 549KB
There is now a large literature on the question of time consistent policy optimisation in both closed and open economies when agents are forward looking. In this section the MSG algorithm is developed further to allow for explicit optimisation of an objective function in a rational expectations model.
The algorithm can be used for many different applications: an economy of rational atomistic agents in which a government optimises an objective function; an economy in which a government and union strategically optimise separate objective functions; two or more open economies in which governments optimise objective functions strategically in a cooperative or non-cooperative manner, with and without strategic interactions with private agents.
The algorithm is developed in terms of strategic interactions between governments in a two-country world. It is based on the dynamic programming algorithm for dynamic games developed in Sachs and Oudiz (1985).
Put simply, the idea is to find a set of feedback rules for government policy (or control variables) from the optimisation of an objective function, where the rules link policy to the current state variables. Associated with the solution, we need to find the current jumping variable also as a function of current state variables. Once we find the rules, then given initial state variable (X0), we can determine initial jumping variables (e0) and therefore we can find a solution to the model. This is discussed more rigorously below.
Consider a general system of equations summarised by:




| where | Xt is a vector of state variables |
| et is a vector of jumping variables (such as forward looking asset prices) | |
| Ut is a vector of control variables (such as monetary and fiscal policies) | |
| τt is a vector of target variables which can include state, jumping or control variables | |
| Et is a vector of exogenous variables | |
| Zt is a vector of endogenous variables that do not effect the dynamics of the system |
18e initial step of the solution technique is to linearise this system around some point, usually either the steady state or a point on the transition path, using a first order Taylor approximation. The impact of the linearisation on the results will depend on several factors. Firstly, if steady state consequences of policies are to be examined then linearising may cause problems. Also, if the model is highly non-linear then the effect of the future path of the economy on the current period may be distorted.
In practice, we have found very little difference between the linear and non-linear versions of the MSG model when examining short-run properties.
Finding numerical derivatives and solving for the endogenous variables (Z) as a function of the other variables in the system, the model can be written:



where each of the coefficient matrices (a1, b2, γ3, etc.) are numerical derivatives evaluated at the point of linearisation[5]and a bar over a variable is the deviation of a variable from the point of linearisation. To avoid excessive notation, the bars over variables will be dropped with the understanding that all future references will be to variables as deviations from some level.
The final assumption added to the above system is that agents take into account all available information in forming expectations about future variables. Agents have rational or model consistent expectations which implies that their expectations of future variables are correct on average. In the current paper we assume perfect foresight so the assumption is:

where a subscript t before a variable indicates the expectation of that variable taken in period t based on the information available in that period.
Now introduce optimising policy-makers. Assume that policy-makers choose the control variables (U) to maximise an intertemporal utility function:

subject to the structure of the economy given in (4.5) to (4.8). When the social welfare function is not explicitly a quadratic loss function, it is made quadratic by linearising using the first two terms of a Taylor's series expansion. The problem for country i becomes to choose a vector of control variables Uit, to maximise:

subject to:


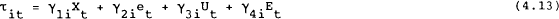
where matrices related to control variables are stacked in the following way:
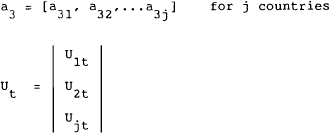
In the case where the system summarises more than one country (or more than one strategic player), several different assumptions can be made. For example, each policy-maker can be assumed to undertake the optimisation taking as given the policies of other governments. This is the Nash-Cournot equilibrium of the dynamic game and is the equilibrium used here to represent non-cooperative behaviour between governments. An alternative is to assume that a central planner undertakes the optimisation of some weighted combination of the two countries' welfare function. This can then be considered the case of cooperation. Other assumptions are possible such as one country or group of countries acting as Stackelberg leaders in formulating policy. These other equilibrium concepts are not explored further here.
Within the class of equilibria considered here, there are various solutions possible depending on the constraints placed on policy-makers by such issues as time consistency and credibility. One solution is to undertake the maximisation of (4.10) in period t and find a path for policy taking as given the expectations of private agents. This is the optimal control solution. Kydland and Prescott (1975) point out that in a model with forward looking agents, the government finding an optimal control solution to a problem in period t will generally find it optimal in period t+1 to deviate from the pre-announced path. The optimal control solution does not satisfy Bellman's criterion for optimality. Once private agents have made decisions based on the announced policy, the problem changes. In a repeated game the pre-announced rule is no longer credible unless the present government can make some form of binding commitment to follow the chosen path of time.
In addition to the issue of time consistency of policies, there is the issue of the form of the rule being followed. The government can choose the entire path of policy settings (open loop policy) or it can choose a rule for the control variables which depend on the realisations of state and exogenous variables (closed loop). Here the focus is on closed loop policies. We also focus on the time consistent policies since they are more likely to be observed in a deterministic world where credibility is difficult to establish.
As mentioned above, the case of optimising governments playing dynamic games and exogenous policy shifts in forward looking models, can both be handled by the same solution technique. The problem is solved in this paper by a technique of dynamic progamming.[6] The technique proposed here is to first solve a finite period optimisation problem where the terminal period is arbitrarily chosen to be some period, T. Solving the problem in period T, gives a solution for the jumping and control variables in period T. The problem is then solved in period T−1, taking as given the policy rules being followed in the next period and the state variables inherited. The forward looking variables are then conditioned on the known future rules. The rules which are found for the finite period problem will be time dimensioned. The second step of the procedure is to find the limit of the finite period problem as T→∞. The limit is found by repeating the backward recursion procedure until rules are found for the control variables and the jumping variables which do not change as the terminal period is moved further away. The case where policy-makers are not optimising is found by setting the rule linking the control variables to the state and exogenous variables to an arbitrary rule or to zero (for no policy action) during the backward recursion. The rule for the jumping variables is therefore the unique stable manifold of the system. The uniqueness derives from the linearity of the system.
This is formally derived as follows.
Define the value function for any country i as:
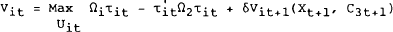
subject to (4.11) to (4.13) where C3t+1 is a constant containing the accumulated values of future exogenous variables.
In solving this problem we are trying to find matrices Γ1 and Γ2, of a linear policy rule:
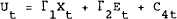
and matrices S1, S2, S3, S4, and S5 such that:
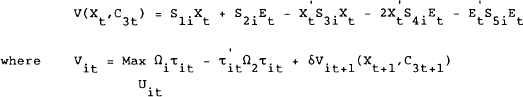
subject to (4.11) to (4.13). We also need to find matrices H1 and H2 that ensure that the jumping variables adjust to keep the model on the stable manifold where:
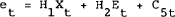
We know that the stable manifold can be expressed in this way due to the solution in Blanchard and Kahn (1980). The iterative technique which solves this problem begins by converting the infinite period problem into a finite period problem where the terminal period is some arbitrary period T. Assume that in period T+1, the jumping variables have stabilised and VT+1(XT+1, C3T+1)=0. This implies:

Substituting (4.14) into (4.12) gives:

The target variables can now be written as a function of state, control, and exogenous variables by substituting (4.15) into (4.13) to find:

This can be substituted into the welfare function (4.10) for period T and the problem written:
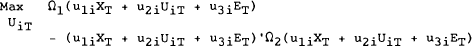
Solving this single period problem, the first order condition for country 1 is:
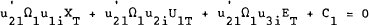
This can be stacked for each country and rewritten:
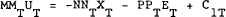
or:

Equation (4.17) gives a rule for the control variables as a function of the state and exogenous variables in period T conditional on the known future. This can be substituted into (4.15) to give a rule for the jumping variables conditional on the known government policy rule.

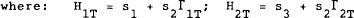
and s2 is a stacked matrix [s2i|s2j] for each country i, j.
The rules for control variables and jumping variables given in (4.17) and (4.18) can be substituted into the equation for the target variables given in (4.13). This can then be substituted into the welfare function to find the value function in period T as a function of the state and exogenous variables in T as well as the constants.

Given the value function in each period and accumulating all future exogenous variables and constants into a constant C3, we can solve the problem in any period t where the policy-maker is to select the vector of control variables, Uit, to maximise:
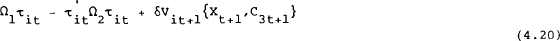
subject to (4.11) to (4.13).
To solve this problem, note that we have Vit+1 as a function of Xt+1. Using the equation of motion of the state variables given in (4.11), we can therefore write Vit+1 as a function of period t variables. The entire problem faced in period t can now be written in terms of period t variables. Consider the specific steps in solving this problem. We have from the solution of the problem in period t+1:

where
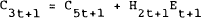
We can substitute the equation for the jumping variables (et+1) from (4.12) and the equation of motion for the state variables (Xt+1) given in (4.11) into (4.21). Simplifying gives:

Equation (4.22) can again be substituted into the equation for the targets given in (4.13) to find:
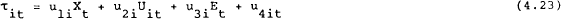
The optimization problem can now be written with the current target variables as a function of the state, control and exogenous variables and the value function Vt+1 as a function of the current state, control and future exogenous variables.
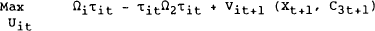
subject to:
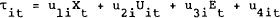
and
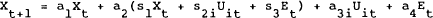
The rewritten problem can now be solved in period t to find:

and

The method described above solves the finite period problem, for an arbitrary terminal period (T). Note that the rule matrices are time subscripted because, in general, the rule in any period will be influenced by the terminal period. To find the solution to the infinite period problem we search for the limit to the backward recursion procedure where the rule matrices become independent of period T. The backward recursion procedure is repeated until the rule matrices converge to a stable value. The convergence is governed by the same conditions required to solve a rational expectation model using the Blanchard-Kahn technique. A necessary condition is that the number of eigenvalues outside the unit circle must be equal to the number of jumping variables.
In any period we can then find the solution to the model by knowing the state variables inherited and the constants which are derived using rules to accumulate all future exogenous variables, as well as future constant policy responses. In this procedure, it is a simple matter to set the policy rules to zero at each step of the iteration. The jumping variable rules summarised in the H matrices ensure that the solution is on the unique stable manifold of the model, given the cumulated future values of the constants derived from the future path of all exogenous variables.
The procedure developed in this section is substantially faster than the other algorithms discussed at the beginning of this chapter, except Blanchard-Kahn, because it is based on a linearized system. It has the added advantage of allowing various simulation exercises to be performed without requiring the recalculation of the rule matrices. Once these are calculated they can be used to simulate any shocks to exogenous variables or initial conditions.