RDP 9208: Credit Supply and Demand and the Australian Economy Appendix A: Maximum – Likelihood Estimation of the Demand and Supply of Business Credit
July 1992
- Download the Paper 638KB
1. The Likelihood Function
The model that we estimate is:
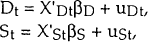
where Dt denotes the quantity demanded during period t, St the quantity supplied during period t, χDt and χSt denote the exogenous variables that influence Dt and St respectively, and uDt and uSt are the residuals. It is assumed that the observed quantity of loans transacted is the minimum of demand and supply. That is, as in any market with voluntary exchange, the short side of the market must prevail. Thus, let Qt be the actual quantity observed during period t:
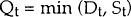
Maddala and Nelson (1974) derive the likelihood function for this model using limited – dependent variable methods.
The probability that the observation Qt belongs to the demand equation is given by:
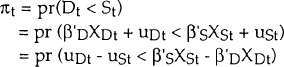
It is assumed that uD and uS are independently and normally distributed, with variances 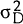 and
and 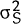 respectively (and that they are also serially independent). Therefore, uD −
uS is normally distributed with variance σ2 = + .
respectively (and that they are also serially independent). Therefore, uD −
uS is normally distributed with variance σ2 = + .
Hence,
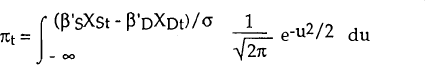
Now define,
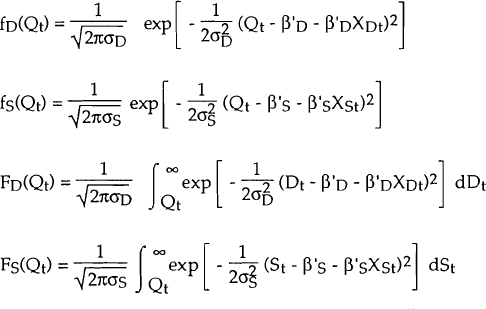
Then, given that Qt belongs to the demand equation, the conditional density of Qt is given by:
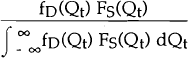
The denominator of this is equal to pr(Dt < St) and, hence, is equal to πt. Thus this can be written as:
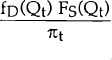
Similarly, the conditional density of Qt, given that Qt belongs to the supply equation, is written as:
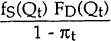
Since Qt lies on the demand equation with probability πt and on the supply equation with probability (1 − πt), the unconditional density of Qt (given the observed values of the exogenous variables χDt, χSt) is as follows:
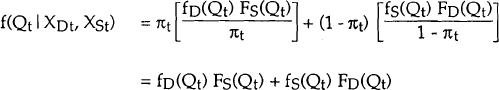
Hence, the log – likelihood, L, may be written as:
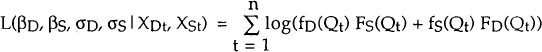
where n is the number of observations.
2. The Estimation Method: Discussion
Parameter estimates were obtained by maximising the log – likelihood using the Broydon, Fletcher, Goldfarb and Shanno (BFGS) maximisation algorithm (which is a modification of the Davidon, Fletcher, Powell method).
A number of caveats are in order when estimating models with unknown sample separation. Firstly, a conceptual problem arises in that too much may be asked of the data when it is not known which observations are on the demand function and which are on the supply function. Monte Carlo methods find that there is considerable loss of information if sample separation is not known. However, empirical results obtained by some other studies using this method are quite good (Maddala (1983) p 299).
Secondly, it can be shown that the likelihood function for this model is unbounded for certain parameter values. However, it has been shown that even if the likelihood function diverges, a consistent estimate of the true parameter value in this model corresponds to a local maximum of the likelihood function, rather than a global maximum. Thus the fact that a local maximum is obtained rather than a global maximum is not a matter of concern, but this result does not ensure that the particular local maximum we have located will give a consistent estimate of the true parameter values.
Finally, the estimate of the covariance matrix produced by the BFGS method may not be precise. The estimated covariance matrix from the BFGS algorithm is (for a well – behaved function) approximately -H, where H is the Hessian of the objective function L. The only exact result that holds for the BFGS method is that if L is quadratic with K free parameters, then after K or more iterations the estimated covariance matrix will be exactly -H (Doan (1988). However, the log-likelihood from our model is considerably more complex than a quadratic function, hence standard errors reported in this paper should be interpreted as a guide to significance, rather than as a precise measure of significance.